Wie Sie einen KI-Use-Case mit der ACE-Formel lesen
Stellen Sie sich Priya vor. Sie leitet ein B2B-Softwareunternehmen mit 75 Mitarbeitern. Das Geschäft läuft gut. Das Produkt wird schnell entwickelt, das Vertriebsteam erreicht seine Ziele, und ihr Vorstand stellt die richtigen Fragen.
Aber letzten Monat änderte sich etwas. Drei separate Anbieter-Pitches landeten in derselben Woche. Ein Sales-Intelligence-Tool. Eine Rechnungsautomatisierungsplattform. Ein KI-Schreibassistent für das Marketing-Team. Jeder Anbieter behauptete, „KI-gestützt" zu sein. Jeder zeigte eine polierte Demo. Jeder versprach, einen Workflow zu „transformieren."
Am Ende der dritten Demo merkte Priya, dass sie alle nach Gefühl statt nach Struktur beurteilte. Ihr gefiel die Benutzeroberfläche beim ersten. Der Vertriebsmitarbeiter beim zweiten war überzeugend. Das dritte hatte eine Case Study von einem Unternehmen, von dem sie schon gehört hatte. Nichts davon war ein Bewertungsrahmen.
Sie bat ihren Operations-Leiter, die drei zu vergleichen. Er kam zwei Tage später zurück. „Ich weiß nicht, wie ich sie vergleichen soll", sagte er. „Sie tun nicht einmal dieselbe Sache."
Er hatte recht. Aber er hatte das Vokabular nicht, um es zu beweisen.
Dieser Artikel gibt Ihnen dieses Vokabular. Sobald Sie das ACE Framework und seine fünf Kernfähigkeiten verstehen, können Sie jedes KI-Produkt in unter fünf Minuten taggen. Priyas Problem hat eine Lösung: ein Fünf-Schritt-Protokoll, fünf durchgearbeitete Beispiele und ein Arbeitsblatt, das ihr Team vor jeder Anbieterevaluation durchführen kann.
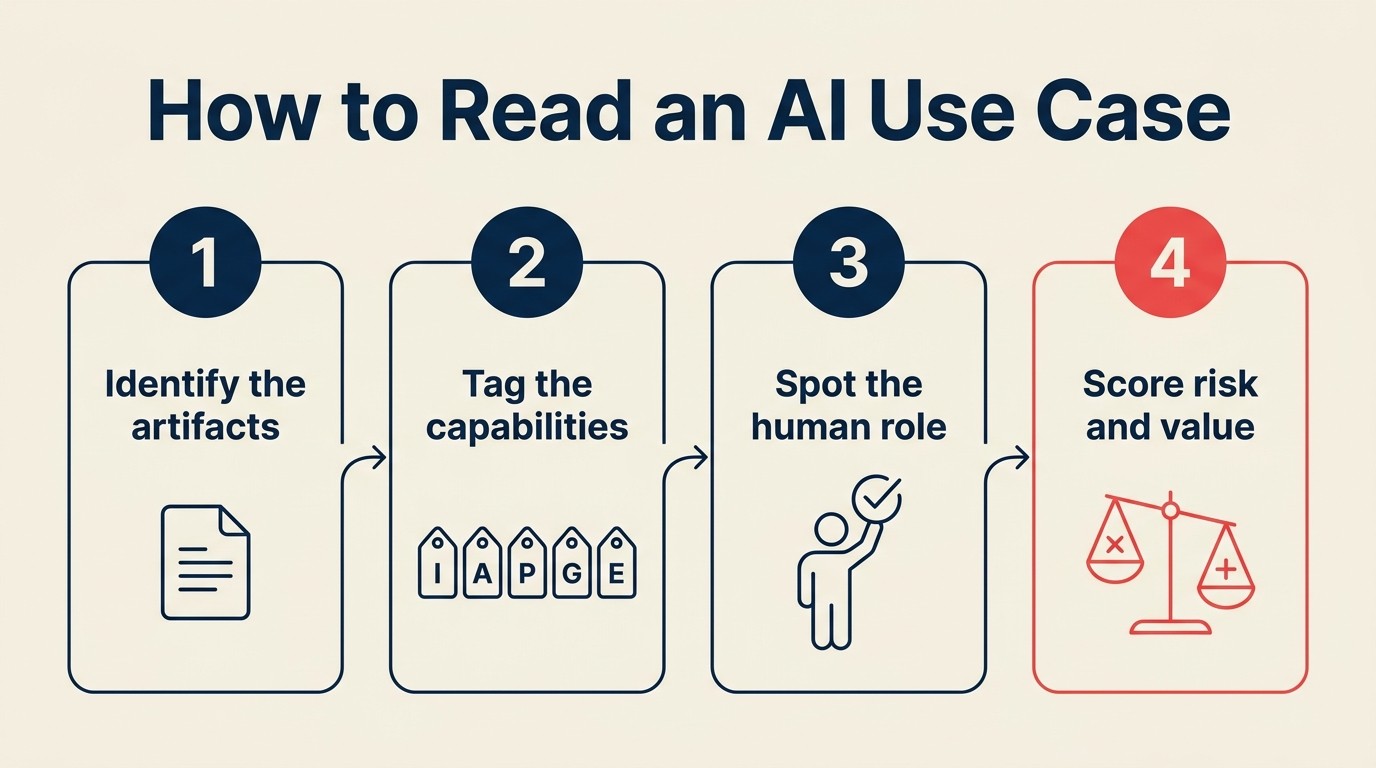
Das ACE-Tagging-Protokoll: 5 Fragen in der richtigen Reihenfolge
Das ACE Framework beschreibt Business-KI als fünf Fähigkeiten, die auf Daten operieren: Ingest, Analyze, Predict, Generate, Execute. Das Tagging-Protokoll wendet diese fünf Konzepte in Folge auf jeden Use Case an. Sie erstellen eine Quittung, keine Ermessensentscheidung.
Stellen Sie diese Fragen in der richtigen Reihenfolge:
Schritt 1: Welche Daten verarbeitet es?
Beginnen Sie beim Fundament. Jede Fähigkeit benötigt Daten, und der Datentyp prägt alles Nachgelagerte. Text? Strukturierte Datensätze? Bilder? Audio? Code? Viele Tools verarbeiten mehrere Typen, aber es gibt in der Regel einen primären. Wenn Sie den Input nicht identifizieren können, können Sie nichts anderes taggen.
Schritt 2: Welche Fähigkeiten nutzt es?
Gehen Sie durch jedes der fünf Verben. Führt es Ingest durch (konvertiert Rohsignale in nutzbare Form)? Analyze (klassifiziert, extrahiert, fasst zusammen)? Predict (berechnet Wahrscheinlichkeiten, prognostiziert Ergebnisse)? Generate (produziert Text, Bilder, Code, Pläne)? Execute (ändert Zustände in einem externen System)? Die meisten realen Produkte verwenden zwei bis vier Fähigkeiten in Folge. Listen Sie alle auf, die zutreffen.
Schritt 3: Was ist das dominante Muster?
Fähigkeitskombinationen clustern sich zu wiederverwendbaren Mustern. Analyze + Predict auf eingehenden Datensätzen ist Scoring und Routing. Ingest auf Audio, das Analyze und Generate speist, ist Meeting Intelligence. Ingest auf Bildern, das Analyze in ein Datenbankupdate führt, ist Vision Extract. Das Muster sagt Ihnen, was benachbarte Tools dasselbe tun und welche Versagensmuster zu erwarten sind.
Schritt 4: Was ist der Output: Artefakt oder Zustandsänderung?
Das ist die Generate-vs.-Execute-Grenze. Generate produziert einen Entwurf: eine E-Mail, einen Score, eine Zusammenfassung, die darauf wartet, dass etwas als nächstes passiert. Execute ändert den externen Zustand: sendet die E-Mail, aktualisiert den CRM-Eintrag, stellt die Rückerstattung aus. Diese Grenze ist relevant für Governance. Ein Tool, das autonom Execute ausführt ohne Ihre Genehmigung, hat ein anderes Risikoprofil als eines, das nur Entwürfe generiert.
Schritt 5: Wo befindet sich der Mensch in der Schleife?
Gibt es ein Review-Gate, bevor etwas ausgeführt wird? Nachträgliches Monitoring? Oder ist die Schleife vollständig autonom? Vollständig autonomes Execute ist die höchste Risikokonfiguration. Es ist manchmal angemessen, aber es sollte eine explizite Designentscheidung sein, keine Auslassung.
Fünf durchgearbeitete Beispiele
Beispiel 1: Salesforce Einstein Lead Scoring
Was es zu tun behauptet: „KI-gestütztes Lead Scoring, das Ihren Vertriebsmitarbeitern sagt, welche Leads priorisiert werden sollen."
ACE-Tagging:
| Frage | Antwort |
|---|---|
| Verarbeitete Daten | Strukturiert (CRM-Datensätze: Firmografien, Deal-Phasenhistorie, Lead-Interaktionen, E-Mail-Öffnungsraten) |
| Fähigkeiten | Analyze (relevante Merkmale aus CRM-Datensätzen extrahieren) + Predict (Wahrscheinlichkeitsscore pro Lead ausgeben) |
| Dominantes Muster | Scoring und Routing |
| Output | Ein Score (Generate), der optional die Auto-Zuweisung auslöst (Execute) |
| Mensch in der Schleife | Vertriebsmitarbeiter überprüfen ihre High-Score-Leads. Manager können Auto-Routing-Regeln konfigurieren |
Was das Ihnen sagt: Einstein ist primär ein Predict-Tool mit einem vorgelagerten Analyze-Schritt. Es schreibt keine E-Mails, analysiert keine Anruf-Audio und aktualisiert keine CRM-Felder eigenständig. Wenn Ihr Team es kauft, um Outreach zu automatisieren, ist das nicht das, was es tut. Die Execute-Fähigkeit (Auto-Routing) existiert, ist aber optional. Die meisten Teams beginnen damit, den Score als Signal für menschliche Vertriebsmitarbeiter zu verwenden, nicht als Trigger für automatisierte Aktionen.
Häufiger Fehler: Von Predict zu erwarten, dass es ohne saubere historische Daten funktioniert. Wenn Ihr CRM keine gelabelten Ergebnisse hat (gewonnene/verlorene Deals verknüpft mit firmografischen Merkmalen), hat das Scoring-Modell nichts, wovon es lernen kann. Saubere historische Daten sind die Voraussetzung. Schmutzige Eingaben, schmutzige Scores.
Beispiel 2: Gong Gesprächsanalyse
Was es zu tun behauptet: „Revenue Intelligence aus Ihren Vertriebsanrufen. KI zeigt, was funktioniert und warum Deals geschlossen werden."
ACE-Tagging:
| Frage | Antwort |
|---|---|
| Verarbeitete Daten | Audio (aufgezeichnete Anrufe) + Text (Transkripte) + Strukturiert (CRM-Datensätze für Deal-Kontext) |
| Fähigkeiten | Ingest (Audio zu Transkript via Speech-to-Text) + Analyze (Themen, Einwände, Sentiment, Gesprächsanteil) + Generate (Anrufzusammenfassung, Coaching-Insights, nächste Schritte) + Execute (CRM-Notizen schreiben, zu Salesforce pushen) |
| Dominantes Muster | Meeting Intelligence |
| Output | Beides. Zusammenfassungen und Coaching-Insights sind Generate (Artefakte zur menschlichen Überprüfung). CRM-Notizaktualisierungen sind Execute (Zustandsänderung) |
| Mensch in der Schleife | Vertriebsmitarbeiter lesen die Zusammenfassung. Manager überprüfen Coaching-Dashboards. Gong handelt nicht gegenüber dem Kunden |
Was das Ihnen sagt: Gong nutzt vier der fünf ACE-Fähigkeiten. Der Ingest-Schritt (Transkriptionsqualität) ist grundlegend: Wenn Anrufe in geräuschvoller Umgebung aufgezeichnet oder die Transkriptionsgenauigkeit niedrig ist, verschlechtert sich jede nachgelagerte Fähigkeit. Der Execute-Schritt (CRM-Rückschreiben) ist real, aber risikoarm: Es aktualisiert ein Notizfeld, sendet keine E-Mails und stellt keine Rückerstattungen aus.
Häufiger Fehler: Gongs Insights als Schlussfolgerungen statt als Signale zu behandeln. Analyze erkennt, dass Vertriebsmitarbeiter, die nach dem Zeitplan fragen, häufiger abschließen. Das ist eine Korrelation aus vergangenen Daten. Es ist ein Impuls zur Untersuchung, kein bewährtes Playbook.
Beispiel 3: ChatGPT schreibt eine Vertriebsemail
Was es zu tun behauptet: Nichts formal. Es ist ein Allzweck-KI-Assistent. In diesem Szenario nutzt ein Vertriebsmitarbeiter es, um eine Akquise-E-Mail zu entwerfen.
ACE-Tagging:
| Frage | Antwort |
|---|---|
| Verarbeitete Daten | Text (die Eingabe des Vertriebsmitarbeiters, der Deal-Kontext, den er einfügt, eventuelle Anweisungen) |
| Fähigkeiten | Analyze (die Eingabe und den Kontext verstehen) + Generate (den E-Mail-Entwurf produzieren) |
| Dominantes Muster | Workflow Copilot (Tool-Modus) |
| Output | Ein Entwurf (nur Generate). Nichts wurde gesendet |
| Mensch in der Schleife | Vollständig in Kontrolle. Der Vertriebsmitarbeiter entscheidet, ob er den Entwurf nutzt, bearbeitet oder verwirft. Execute ist separat und manuell |
Was das Ihnen sagt: ChatGPT so eingesetzt ist ein reines Generate-Tool. Es hat keinen Zugang zu Ihrem CRM, kann nichts senden und weiß nichts über den tatsächlichen Interessenten außer dem, was der Vertriebsmitarbeiter einfügt. Das Risikoprofil ist niedrig: Im schlimmsten Fall ist es ein schlechter Entwurf, der verworfen wird. Aber das ist auch der Grund, warum die Produktivitätsdecke begrenzt ist. Jeder Output erfordert, dass ein Mensch ihn überprüft und sendet.
Das ist die einfachste ACE-Formel in der Praxis. Analyze + Generate, kein Execute, Mensch entscheidet alles. Sobald Sie es so taggen, wird der Vergleich mit einem autonomen SDR-Agenten (der Execute hinzufügt und das menschliche Gate entfernt) viel schärfer.
Beispiel 4: Bill.com KI-Rechnungsautomatisierung
Was es zu tun behauptet: „Rechnungserfassung und -buchung automatisieren. KI extrahiert Daten aus Ihren Rechnungen und leitet sie zur Genehmigung weiter."
ACE-Tagging:
| Frage | Antwort |
|---|---|
| Verarbeitete Daten | Bild (Rechnungsscans, PDFs) + Strukturiert (Lieferantenstammdaten, Kontenrahmen) |
| Fähigkeiten | Ingest (OCR und Dokumentenanalyse auf Rechnungsbild) + Analyze (Lieferantenname, Positionen, Beträge, GL-Codes extrahieren) + Execute (Rechnungseintrag erstellen, Zahlungsplan festlegen, zur Genehmigung weiterleiten) |
| Dominantes Muster | Vision Extract |
| Output | Extrahierte strukturierte Daten (Analyze-Output) werden ein aktiver Rechnungseintrag (Execute) |
| Mensch in der Schleife | Genehmigungsgates vorhanden. Rechnungen über einem konfigurierbaren Dollarbetrag erfordern menschliche Unterschrift vor der Zahlung |
Was das Ihnen sagt: Der Ingest-Schritt ist der Ursprung der meisten Genauigkeitsprobleme: handausgefüllte Formulare, ungewöhnliche Layouts und Scans mit niedriger Auflösung verschlechtern alle die OCR. Der Execute-Schritt hat echte Konsequenzen: Zahlungspläne und Genehmigungswarteschlangen sind aktive Einträge in Ihrem System. Das menschliche Genehmigungsgate ist das richtige Design, muss aber explizit konfiguriert werden. Die meisten Teams unterschätzen, wie wichtig der Dollarschwellenwert ist.
Häufiger Fehler: Den Genehmigungsschwellenwert zu hoch setzen (z. B. 5.000 €) und davon ausgehen, dass alles darunter risikoarm ist. Eine Welle kleiner Duplikatrechnungen desselben Lieferanten zu je 800 € kann durchrutschen. Die Analyze-Fähigkeit sucht nicht nach Duplikaten, es sei denn, diese Logik ist explizit eingebaut.
Beispiel 5: Cursor und Claude Code (autonome Coding-Agenten)
Was es zu tun behauptet: „Ein KI-Coding-Agent, der Ihre Codebasis liest, Code nach Spezifikation schreibt, Tests ausführt und einen Pull Request öffnet."
ACE-Tagging:
| Frage | Antwort |
|---|---|
| Verarbeitete Daten | Code (das Repository, vorhandene Dateien, vergangene Pull Requests) + Text (die Spezifikation oder Problembeschreibung, Nutzeranweisungen) |
| Fähigkeiten | Alle fünf. Ingest (Codebasis lesen und parsen) + Analyze (die vorhandene Struktur verstehen, relevante Dateien finden) + Predict (den wahrscheinlichsten korrekten Implementierungsansatz bestimmen) + Generate (die Code-Änderungen schreiben) + Execute (Tests ausführen, Pull Request erstellen, optional mergen) |
| Dominantes Muster | Autonomer Agent |
| Output | Code-Änderungen sind Generate. Pull-Request-Erstellung und Testausführung sind Execute. Merge (wenn konfiguriert) ist Execute mit hoher Konsequenz |
| Mensch in der Schleife | Überprüft den Pull Request vor dem Merge. Das ist das kritische Gate. Ohne es erreicht Execute die Produktion |
Was das Ihnen sagt: Alle fünf ACE-Fähigkeiten sind aktiv, was bedeutet, dass alle fünf Versagensmuster gleichzeitig aktiv sind. Ingest kann eine unbekannte Codebasis falsch lesen. Analyze kann relevante Dateien falsch identifizieren. Predict kann einen Implementierungsansatz wählen, der technisch korrekt, aber architektonisch falsch ist. Generate kann Code schreiben, der Tests besteht, aber subtile Logikfehler einführt. Execute (der Merge) ist in der Produktion irreversibel.
Das Pull-Request-vor-Merge-Gate ist der einzige Punkt, an dem ein Mensch Fehler aus allen vier vorangegangenen Fähigkeiten abfangen kann. Teams, die es entfernen, um Deployment-Pipelines „vollständig zu automatisieren", entfernen das Sicherheitsventil an allen fünf Versagensmustern gleichzeitig.
Erwähnenswert: Cursor und Claude Code unterscheiden sich im Umfang. Cursor ist primär ein Workflow Copilot (Generate-lastig, Mensch steuert jeden Schritt in der IDE). Claude Code kann autonomer operieren (Execute-fähig, mehrstufige Aufgaben). Das Taggen beider erzwingt die Unterscheidung, die „KI-Coding-Tool" völlig verbirgt.
Ihr Turn: Das Audit-Arbeitsblatt
Führen Sie dieses Audit für drei KI-Tools durch, die Ihr Team gerade nutzt. Beginnen Sie nicht mit der Anbieterdokumentation. Beginnen Sie damit, was das Tool in Ihrem Workflow tatsächlich tut, und kartieren Sie dann rückwärts.
Füllen Sie für jedes Tool diese Tabelle aus:
| Feld | Ihre Antwort |
|---|---|
| Tool-Name | |
| Was verarbeitet es? (Datentypen) | |
| Welche ACE-Fähigkeiten nutzt es? | |
| Welchem Muster entspricht es? | |
| Ist der Output ein Entwurf (Generate) oder eine Zustandsänderung (Execute)? | |
| Wo befindet sich der Mensch in der Schleife? | |
| Was passiert, wenn die KI bei jeder Fähigkeit falsch liegt? |
Beantworten Sie dann diese drei Fragen:
- Welche Fähigkeit dominiert? (Die, die den meisten Wert des Tools antreibt.)
- Führt es Execute aus? Wenn ja, sind die Execute-Leitplanken explizit dokumentiert oder angenommen?
- Beim Vergleich zweier Tools in derselben Kategorie: Nutzen sie dieselbe ACE-Formel oder unterschiedliche?
Frage drei ist die aufschlussreichste. Zwei CRM-Intelligence-Tools können in einer Demo identisch aussehen, aber völlig unterschiedliche Fähigkeitskombinationen nutzen. Eines ist Analyze + Generate (fasst Deal-Notizen zusammen, entwirft nächste Schritte). Ein anderes ist Analyze + Predict + Execute (bewertet Deal-Gesundheit, prognostiziert Abschluss, leitet gefährdete Deals automatisch an einen Manager weiter). Das ACE-Tagging macht diesen Unterschied in 10 Minuten sichtbar, statt in einer 60-minütigen Demo.
Häufige Fehler beim Taggen
Fehler 1: Analyze und Predict verwechseln.
Analyze beantwortet „Was ist das?" Predict beantwortet „Was ist wahrscheinlich als nächstes?" Ein Tool, das Support-Tickets nach Typ klassifiziert, ist Analyze. Ein Tool, das bewertet, welche Tickets wahrscheinlich zu Churn eskalieren, ist Predict (mit Analyze als Input). Sie scheitern auch unterschiedlich. Analyze-Fehler zeigen sich sofort (falsche Klassifikation). Predict-Fehler zeigen sich Wochen später, wenn Wahrscheinlichkeitsschätzungen von der Realität abweichen.
Fehler 2: Execute übersehen.
Teams zählen Execute zu wenig, weil es im Hintergrund stattfindet. Ein Meeting-Intelligence-Tool, das „Ihr CRM nach Anrufen aktualisiert", führt Execute aus. Ein Lead-Scoring-Tool, das „automatisch dem richtigen Vertriebsmitarbeiter zuweist", führt Execute aus. Wenn Sie nur das Dashboard sehen, übersehen Sie die API-Aufrufe, die bereits Datensätze in Ihrem System ändern. Gehen Sie die Integrationseinstellungen durch, nicht nur die Oberfläche. Schreibberechtigungen, Webhooks, Automatisierungstrigger — das ist Execute.
Fehler 3: Datentypen underzählen.
Gong verarbeitet nicht nur Audio. Es ingested den CRM-Eintrag, das Anruf-Audio und das Transkript gleichzeitig. Das Audio trägt das Signal, aber der CRM-Kontext (Deal-Phase, Unternehmensgröße, Vertriebsmitarbeiter) ist das, was Analyze und Predict nützlich macht. Nur den primären Kanal taggen bedeutet, die Datenabhängigkeiten zu übersehen — und die Versagensmuster, die auftreten, wenn sekundäre Inputs unordentlich sind.
Fehler 4: Fähigkeiten ohne Muster auflisten.
Eine Liste von Fähigkeiten ist eine Teileliste. Ein Muster ist die Baugruppe. Zwei Tools könnten beide Analyze + Generate nutzen, aber eines ist ein Workflow Copilot (menschengesteuert, einzelner Output, iterativ) und das andere ist eine Document-Review-Engine (stapelverarbeitet, mehrdokumentig, strukturierter Output). Das Muster sagt Ihnen, welche Versagensmuster am wahrscheinlichsten sind und welche Workflow-Änderungen das Tool erfordert. Fähigkeiten ohne Muster ist ein halbes Tag.
ACE-Tags für Kaufentscheidungen nutzen
Redundanzen in Ihrem Stack finden. Taggen Sie alle Ihre aktuellen KI-Tools und legen Sie die Ergebnisse nebeneinander. Drei Tools, die Analyze + Generate auf Text ausführen, sind eine Konsolidierungsmöglichkeit. Null Tools, die Predict ausführen, obwohl Sie für „prädiktive Analytik" bezahlen, ist eine Lücke. Die Tags zeigen Ihnen die Form Ihrer tatsächlichen KI-Investition — die oft anders ist als Sie denken.
Tools ehrlich vergleichen. Zwei „KI-Vertriebstools" können völlig unterschiedliche ACE-Formeln nutzen. Wenn eines Analyze + Generate ist und das andere Analyze + Predict + Execute, lösen sie unterschiedliche Probleme. Sie vergleichen einen Copilot mit einer Automatisierungsmaschine. Dieser Unterschied sollte Ihre Bewertungskriterien bestimmen, nicht die Demo-Qualität.
Die Formel dem tatsächlichen Bedarf anpassen. Die meisten Kauffehler passieren, weil Teams wissen, dass sie „KI für X" wollen, aber nicht identifiziert haben, welche Fähigkeit sie für X benötigen. Vertriebsmitarbeiter-Produktivität (schneller entwerfen)? Sie brauchen Generate. Priorisierung (auf welche Deals fokussieren)? Sie brauchen Predict. Manuelle Dateneingabe aus Dokumenten? Sie brauchen Ingest + Analyze + Execute. Mit der Fähigkeitsanforderung zu beginnen statt mit dem Kategorie-Label bringt Sie schneller zur richtigen Shortlist.
Ein Hinweis: Das Tagging-Protokoll ist eine Diagnose, kein Score. Ein Tool mit fünf Fähigkeiten ist nicht besser als eines mit zwei. Ein schlecht gestalteter autonomer Agent mit allen fünf ist riskanter als ein einfacher Generate-only-Copilot. Was zählt, ist ob die Fähigkeitsmischung Ihr tatsächliches Problem löst, ob Execute-Schritte angemessen abgesichert sind, und ob die Daten, die das System speisen, sauber genug sind, um ihnen zu vertrauen.
Den Reflex aufbauen
Das Ziel ist nicht, jedes Tool beim ersten Versuch perfekt zu taggen. Das Ziel ist, den Reflex aufzubauen.
Beginnen Sie mit den fünf Fähigkeiten als mentale Checkliste bei Demos. Wenn ein Anbieter sagt „unsere KI analysiert Ihre Daten", fragen Sie: Ist das Analyze (aktueller Zustand) oder Predict (zukünftige Wahrscheinlichkeit)? Wenn er sagt „automatisiert Ihren Workflow", fragen Sie: Erzeugt es Entwürfe oder führt es Aktionen aus? Wenn er sagt „intelligentes Routing", fragen Sie, ob Execute vorhanden ist und was der menschliche Genehmigungsmechanismus ist.
Nach einem Monat davon lesen Sie Pitches anders. Priyas Drei-Anbieter-Problem wird zu einem 15-minütigen Vergleich statt einem 60-minütigen Bauchgefühl-Check. Und Initiativen taggen wird zum ersten Schritt in jedem Projekt-Brief, nicht als Nachgedanke.
Fünf Verben. Sechs Datentypen. Zehn Muster. Die Übung ist das, was es festigt.
Dieser Artikel ist Teil der ACE Framework Foundation-Kollektion. Verwandte Lektüre: die Generate-vs.-Execute-Grenze, KI-Initiativen taggen, und die Tieftauchgänge zu Predict und Execute.

Senior Operations & Growth Strategist
On this page
- Das ACE-Tagging-Protokoll: 5 Fragen in der richtigen Reihenfolge
- Fünf durchgearbeitete Beispiele
- Beispiel 1: Salesforce Einstein Lead Scoring
- Beispiel 2: Gong Gesprächsanalyse
- Beispiel 3: ChatGPT schreibt eine Vertriebsemail
- Beispiel 4: Bill.com KI-Rechnungsautomatisierung
- Beispiel 5: Cursor und Claude Code (autonome Coding-Agenten)
- Ihr Turn: Das Audit-Arbeitsblatt
- Häufige Fehler beim Taggen
- ACE-Tags für Kaufentscheidungen nutzen
- Den Reflex aufbauen