Como Ler um Caso de Uso de AI Usando a Fórmula ACE
Conheça Priya. Ela gerencia uma empresa de software B2B com 75 funcionários. Os negócios vão bem. O produto está sendo lançado rapidamente, a equipe de vendas está batendo cota e seu conselho está fazendo as perguntas certas.
Mas no mês passado, algo mudou. Três pitches de fornecedores distintos chegaram na mesma semana. Uma ferramenta de inteligência de vendas. Uma plataforma de automação de notas fiscais. Um assistente de escrita com AI para a equipe de marketing. Cada fornecedor afirmava ser "movido por AI." Cada um mostrou uma Demo polida. Cada um prometia "transformar" um Workflow.
Ao final da terceira Demo, Priya percebeu que estava julgando todos eles pela sensação, não pela estrutura. Ela gostou da interface do primeiro. O vendedor do segundo era convincente. O terceiro tinha um case study de uma empresa que ela conhecia. Nada disso era um framework de compra.
Ela pediu ao seu Diretor de Operações para comparar os três. Ele voltou dois dias depois. "Não sei como compará-los," disse ele. "Eles nem estão fazendo a mesma coisa."
Ele estava certo. Mas não tinha o vocabulário para provar isso.
Este artigo oferece esse vocabulário. Uma vez que você entende o ACE Framework e suas cinco capabilities principais, você consegue fazer o tagging de qualquer produto de AI em menos de cinco minutos. O problema de Priya tem uma solução: um protocolo de cinco passos, cinco exemplos práticos e uma planilha que sua equipe pode usar antes de qualquer avaliação de fornecedor.
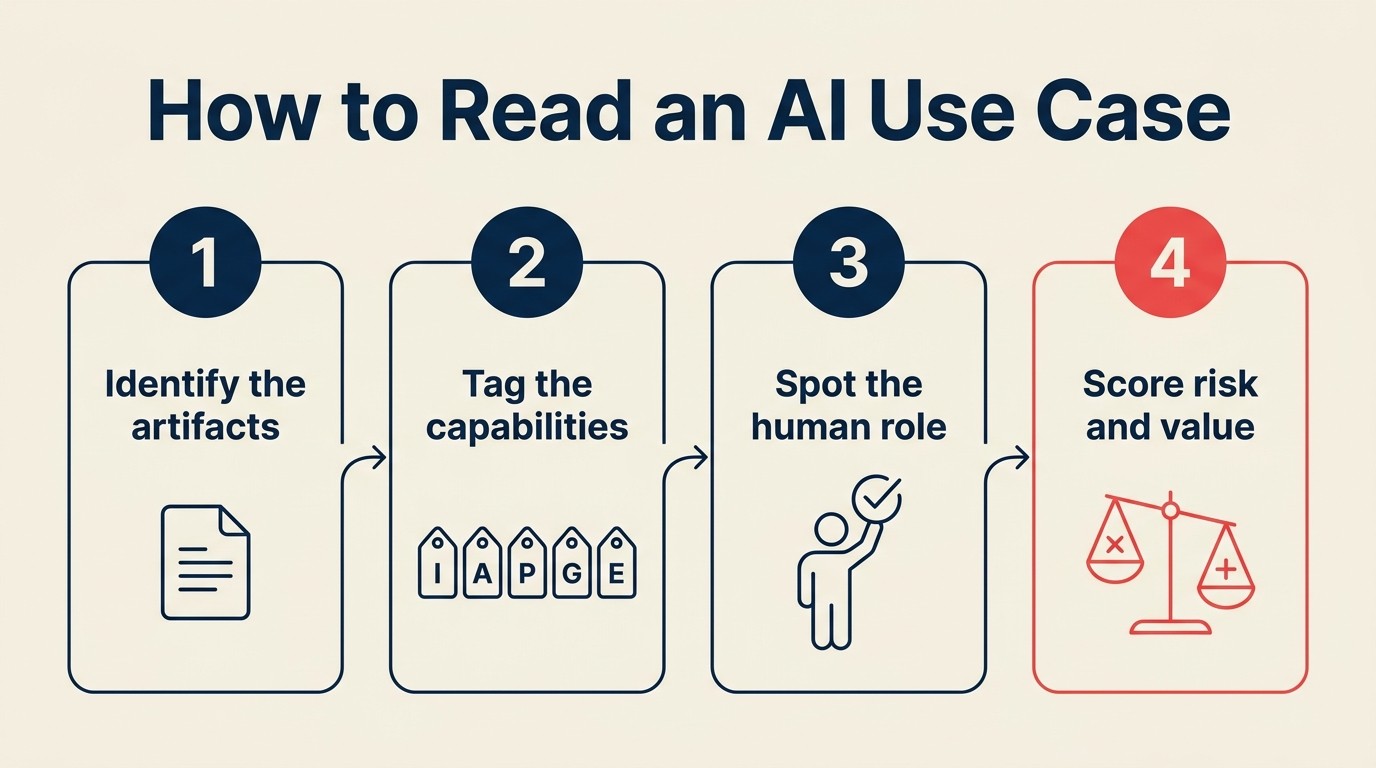
O protocolo de tagging ACE: 5 perguntas em ordem
O ACE Framework descreve a AI nos negócios como cinco capabilities operando sobre dados: Ingest, Analyze, Predict, Generate, Execute. O protocolo de tagging aplica esses cinco conceitos em sequência a qualquer caso de uso. Você está construindo um recibo, não um julgamento subjetivo.
Faça essas perguntas em ordem:
Passo 1: Quais dados ele consome?
Comece pela fundação. Toda capability precisa de dados, e o tipo de dado molda tudo o que vem a seguir. Texto? Registros estruturados? Imagens? Áudio? Código? Muitas ferramentas consomem múltiplos tipos, mas geralmente há um primário. Se você não consegue identificar o input, não consegue fazer o tagging de mais nada.
Passo 2: Quais capabilities ela usa?
Percorra cada um dos cinco verbos. Ela faz Ingest (converte sinais brutos em forma utilizável)? Analyze (classifica, extrai, resume)? Predict (calcula probabilidades, prevê resultados)? Generate (produz texto, imagens, código, planos)? Execute (muda estado em um sistema externo)? A maioria dos produtos reais usa duas a quatro capabilities em sequência. Liste todas que se aplicam.
Passo 3: Qual é o padrão dominante?
Combinações de capabilities se agrupam em padrões reutilizáveis. Analyze + Predict em registros de entrada é Scoring e Roteamento. Ingest em áudio alimentando Analyze e Generate é Inteligência de Reuniões. Ingest em imagens alimentando Analyze em uma atualização de registro é Vision Extract. O padrão diz quais ferramentas adjacentes fazem o mesmo trabalho e quais modos de falha esperar.
Passo 4: O output é um artefato ou uma mudança de estado?
Esta é a fronteira entre Generate e Execute. Generate produz um rascunho: um e-mail, uma pontuação, um resumo que fica aguardando que algo aconteça em seguida. Execute muda o estado externo: envia o e-mail, atualiza o registro no CRM, processa o reembolso. Essa fronteira importa para a governança. Uma ferramenta que Executa autonomamente sem sua aprovação tem um perfil de risco diferente de uma que apenas Gera rascunhos.
Passo 5: Onde o humano se encaixa no loop?
Há um portão de revisão antes que qualquer coisa Execute? Monitoramento após o fato? Ou o loop é totalmente autônomo? Execute totalmente autônomo é a configuração de maior risco. É apropriado às vezes, mas deve ser uma decisão de design explícita, não um descuido.
Cinco exemplos práticos
Exemplo 1: Lead scoring do Salesforce Einstein
O que afirma fazer: "Lead scoring movido por AI que diz aos seus representantes quais leads priorizar."
Tagging ACE:
| Pergunta | Resposta |
|---|---|
| Dados consumidos | Estruturado (registros de CRM: firmografia, histórico de estágio de negociação, interações com leads, taxas de abertura de e-mail) |
| Capabilities | Analyze (extrai features relevantes de registros de CRM) + Predict (gera uma pontuação de probabilidade por lead) |
| Padrão dominante | Scoring e Roteamento |
| Output | Uma pontuação (Generate) que opcionalmente aciona atribuição automática (Execute) |
| Humano no loop | Representantes revisam seus leads de alta pontuação. Gerentes podem configurar regras de auto-roteamento |
O que isso lhe diz: O Einstein é primariamente uma ferramenta de Predict com uma etapa de pré-processamento de Analyze. Não escreve e-mails, analisa áudio de ligações ou atualiza campos de CRM por conta própria. Se sua equipe está comprando-o para automatizar o outreach, não é isso que ele faz. A capability Execute (auto-roteamento) existe, mas é opcional. A maioria das equipes começa com a pontuação como sinal para representantes humanos, não como gatilho para ação automatizada.
Erro comum: Esperar que Predict funcione sem dados históricos limpos. Se seu CRM não tem resultados rotulados (registros de ganho/perda ligados a features firmográficas), o modelo de pontuação não tem nada para aprender. Dados históricos limpos são o pré-requisito. Garbage in, pontuações garbage out.
Exemplo 2: Análise de ligações do Gong
O que afirma fazer: "Inteligência de receita a partir das suas ligações de vendas. A AI destaca o que está funcionando e por que os negócios fecham."
Tagging ACE:
| Pergunta | Resposta |
|---|---|
| Dados consumidos | Áudio (ligações gravadas) + Texto (transcrições) + Estruturado (registros de CRM para contexto da negociação) |
| Capabilities | Ingest (áudio para transcrição via fala para texto) + Analyze (tópicos, objeções, sentimento, proporção de tempo de fala) + Generate (resumo da ligação, insights de coaching, sugestões de próximos passos) + Execute (escrever notas no CRM, enviar para o Salesforce) |
| Padrão dominante | Inteligência de Reuniões |
| Output | Ambos. Resumos e insights de coaching são Generate (artefatos para revisão humana). Atualizações de notas no CRM são Execute (mudança de estado) |
| Humano no loop | Representantes leem o resumo. Gerentes revisam Dashboards de coaching. O Gong não toma ação sobre o cliente |
O que isso lhe diz: O Gong usa quatro das cinco capabilities ACE. A etapa de Ingest (qualidade da transcrição) é fundamental: se as ligações são gravadas em ambientes ruidosos ou a precisão da transcrição é baixa, toda capability downstream se degrada. A etapa de Execute (write-back no CRM) é real, mas de baixo risco: está atualizando um campo de notas, não enviando um e-mail ou processando um reembolso.
Erro comum: Tratar os insights do Gong como conclusões em vez de sinais. O Analyze sinaliza que representantes que perguntam sobre prazo fecham a taxas mais altas. Isso é uma correlação de dados passados. É um prompt para investigar, não um playbook comprovado.
Exemplo 3: ChatGPT escrevendo um e-mail de vendas
O que afirma fazer: Nada formalmente. É um assistente de AI de uso geral. Neste cenário, um representante o usa para redigir um outreach.
Tagging ACE:
| Pergunta | Resposta |
|---|---|
| Dados consumidos | Texto (o prompt do representante, o contexto da negociação que ele cola, quaisquer instruções) |
| Capabilities | Analyze (compreende o prompt e o contexto) + Generate (produz o rascunho do e-mail) |
| Padrão dominante | Copilot de Workflow (modo ferramenta) |
| Output | Um rascunho (somente Generate). Nada foi enviado |
| Humano no loop | Totalmente no controle. O representante decide se usa o rascunho, o edita ou o descarta. Execute é separado e manual |
O que isso lhe diz: O ChatGPT usado dessa forma é uma ferramenta puramente de Generate. Não tem acesso ao seu CRM, não consegue enviar nada e não sabe nada sobre o prospect real além do que o representante colou. O perfil de risco é baixo: o pior caso é um rascunho ruim que é descartado. Mas também é por isso que o teto de produtividade é limitado. Todo output requer que um humano verifique e dispare.
Este é o ACE Formula mais simples na prática. Analyze + Generate, sem Execute, humano decide tudo. Uma vez que você faz o tagging assim, a comparação com um agente SDR autônomo (que adiciona Execute e remove o portão humano) se torna muito mais nítida.
Exemplo 4: Automação de notas fiscais do Bill.com com AI
O que afirma fazer: "Automatize a captura e codificação de notas fiscais. A AI extrai dados das suas notas fiscais e as encaminha para aprovação."
Tagging ACE:
| Pergunta | Resposta |
|---|---|
| Dados consumidos | Imagem (scans de notas fiscais, PDFs) + Estruturado (cadastro de fornecedores, plano de contas) |
| Capabilities | Ingest (OCR e análise de documentos na imagem da nota fiscal) + Analyze (extrai nome do fornecedor, itens, valores, códigos GL) + Execute (cria registro de nota fiscal, define cronograma de pagamento, encaminha para aprovação) |
| Padrão dominante | Vision Extract |
| Output | Dados estruturados extraídos (output de Analyze) se tornam um registro de nota fiscal ativo (Execute) |
| Humano no loop | Portões de aprovação existem. Notas fiscais acima de um threshold de valor configurável requerem aprovação humana antes do pagamento |
O que isso lhe diz: A etapa de Ingest é onde a maioria dos problemas de precisão se origina: formulários preenchidos à mão, layouts incomuns e scans de baixa resolução degradam o OCR. A etapa de Execute tem consequências reais: cronogramas de pagamento e filas de aprovação são registros ativos no seu sistema. O portão de aprovação humana é o design correto, mas precisa ser configurado explicitamente. A maioria das equipes subestima o quanto o threshold de valor importa.
Erro comum: Definir o threshold de aprovação muito alto (digamos, R$ 5.000) e assumir que tudo abaixo é de baixo risco. Uma onda de pequenas notas fiscais duplicadas do mesmo fornecedor em R$ 800 cada pode passar despercebida. A capability Analyze não verifica duplicatas a menos que essa lógica seja explicitamente construída.
Exemplo 5: Cursor e Claude Code (agentes de codificação autônomos)
O que afirma fazer: "Um agente de codificação com AI que lê sua base de código, escreve código conforme a especificação, executa testes e abre um pull request."
Tagging ACE:
| Pergunta | Resposta |
|---|---|
| Dados consumidos | Código (o repositório, arquivos existentes, PRs anteriores) + Texto (a spec ou descrição do issue, instruções do usuário) |
| Capabilities | Todas as cinco. Ingest (lê e analisa a base de código) + Analyze (entende a estrutura existente, encontra os arquivos relevantes) + Predict (determina a abordagem de implementação mais provavelmente correta) + Generate (escreve as alterações de código) + Execute (executa testes, cria o PR, opcionalmente faz merge) |
| Padrão dominante | Agente Autônomo |
| Output | Alterações de código são Generate. Criação de PR e execução de testes são Execute. Merge (se configurado) é Execute com alta consequência |
| Humano no loop | Revisa o PR antes do merge. Este é o portão crítico. Sem ele, Execute chega à produção |
O que isso lhe diz: Todas as cinco capabilities ACE estão ativas, o que significa que todos os cinco modos de falha estão ativos simultaneamente. Ingest pode ler incorretamente uma base de código desconhecida. Analyze pode identificar erroneamente arquivos relevantes. Predict pode escolher uma implementação tecnicamente correta, mas arquiteturalmente errada. Generate pode escrever código que passa nos testes, mas introduz erros lógicos sutis. Execute (o merge) é irreversível em produção.
O portão de PR-antes-do-merge é o único ponto onde um humano pode capturar falhas de qualquer uma das quatro capabilities anteriores. Equipes que o removem para "automatizar completamente" os pipelines de deploy estão removendo a válvula de segurança de todos os cinco modos de falha de uma vez.
Vale notar: Cursor e Claude Code diferem em escopo. Cursor é primariamente um Copilot de Workflow (Generate-intensivo, humano conduz cada passo no IDE). Claude Code pode operar de forma mais autônoma (Execute-capaz, tarefas de múltiplos passos). Fazer o tagging de ambos força a distinção que "ferramenta de codificação com AI" esconde completamente.
Sua vez: a planilha de auditoria
Execute isso para três ferramentas de AI que sua equipe usa agora. Não comece com a documentação do fornecedor. Comece com o que a ferramenta realmente faz no seu Workflow, depois mapeie para trás.
Para cada ferramenta, complete esta tabela:
| Campo | Sua resposta |
|---|---|
| Nome da ferramenta | |
| O que ela consome? (tipos de dados) | |
| Quais capabilities ACE ela usa? | |
| A qual padrão ela corresponde? | |
| O output é um rascunho (Generate) ou uma mudança de estado (Execute)? | |
| Onde está o humano no loop? | |
| O que acontece se a AI estiver errada em cada capability? |
Então responda estas três perguntas:
- Qual capability domina? (A que impulsiona a maior parte da proposta de valor da ferramenta.)
- Ela Executa? Se sim, os guardrails de Execute são explícitos e documentados, ou assumidos?
- Comparando duas ferramentas que você usa na mesma categoria: elas estão usando a mesma fórmula ACE, ou fórmulas diferentes?
A pergunta três é a reveladora. Duas ferramentas de "inteligência de vendas para CRM" podem parecer idênticas em uma Demo, mas usar combinações de capabilities completamente diferentes. Uma é Analyze + Generate (resume notas de negociação, redige próximos passos). Outra é Analyze + Predict + Execute (pontua a saúde da negociação, prevê fechamento, auto-encaminha negociações em risco para um gerente). O tagging ACE revela essa diferença em 10 minutos em vez de uma Demo de 60 minutos.
Erros comuns ao fazer o tagging
Erro 1: Confundir Analyze com Predict.
Analyze responde "o que é isso?" Predict responde "o que provavelmente vem a seguir?" Uma ferramenta que classifica tickets de suporte por tipo é Analyze. Uma ferramenta que pontua quais tickets provavelmente vão escalar para churn é Predict (com Analyze como input). Eles também falham de formas diferentes. A falha de Analyze aparece imediatamente (classificação errada). A falha de Predict aparece semanas depois, quando as estimativas de probabilidade derivam da realidade.
Erro 2: Perder o Execute.
As equipes subestimam o Execute porque ele fica nos bastidores. Uma ferramenta de inteligência de reuniões que "atualiza seu CRM após as ligações" está Executando. Uma ferramenta de lead scoring que "auto-atribui ao representante certo" está Executando. Se você só vê o Dashboard, perde as chamadas de API que já estão mudando registros no seu sistema. Percorra as configurações de integração, não apenas a interface. Permissões de escrita, webhooks, gatilhos de automação — esses são Execute.
Erro 3: Subcontar tipos de dados.
O Gong não está apenas processando áudio. Está ingerindo o registro de CRM, o áudio da ligação e a transcrição simultaneamente. O áudio carrega o sinal, mas o contexto de CRM (estágio da negociação, tamanho da empresa, representante) é o que torna Analyze e Predict úteis. Faça o tagging apenas do canal primário e você perderá as dependências de dados — e os modos de falha que aparecem quando os inputs secundários estão bagunçados.
Erro 4: Listar capabilities sem nomear o padrão.
Uma lista de capabilities é uma lista de peças. Um padrão é a montagem. Duas ferramentas podem usar Analyze + Generate, mas uma é um Copilot de Workflow (conduzido por humano, output único, iterativo) e a outra é um motor de Revisão de Documentos (processado em lote, múltiplos documentos, output estruturado). O padrão diz quais modos de falha são mais prováveis e quais mudanças de Workflow a ferramenta requer. Capabilities sem um padrão é um tagging incompleto.
Usando tags ACE para decisões de compra
Encontre redundância no seu stack. Faça o tagging de todas as suas ferramentas de AI atuais e coloque os resultados lado a lado. Três ferramentas fazendo Analyze + Generate em texto é uma oportunidade de consolidação. Zero ferramentas fazendo Predict apesar de pagar por "análise preditiva" é uma lacuna. As tags mostram o formato do seu investimento real em AI, que geralmente é diferente do que você pensa que tem.
Compare ferramentas honestamente. Duas "ferramentas de vendas com AI" podem usar fórmulas ACE completamente diferentes. Se uma é Analyze + Generate e a outra é Analyze + Predict + Execute, elas estão resolvendo problemas diferentes. Você está comparando um copilot a um motor de automação. Essa distinção deve conduzir seus critérios de avaliação, não a qualidade da Demo.
Combine a fórmula com a necessidade real. A maioria dos erros de compra acontece porque as equipes sabem que querem "AI para X" mas não identificaram qual capability precisam para X. Produtividade de representantes (redigir mais rápido)? Você precisa de Generate. Priorização (em quais negociações focar)? Você precisa de Predict. Entrada manual de dados a partir de documentos? Você precisa de Ingest + Analyze + Execute. Começar com a necessidade de capability, não o rótulo de categoria, leva você à lista certa mais rapidamente.
Uma observação: o protocolo de tagging é um diagnóstico, não uma pontuação. Uma ferramenta com cinco capabilities não é melhor que uma com duas. Um Agente Autônomo mal governado usando todas as cinco é mais arriscado do que um copilot simples apenas de Generate. O que importa é se o mix de capabilities resolve seu problema real, se as etapas de Execute são adequadamente protegidas e se os dados que alimentam o sistema são limpos o suficiente para confiar.
Construindo o reflexo
O objetivo não é fazer o tagging de cada ferramenta perfeitamente na primeira tentativa. O objetivo é construir o reflexo.
Comece com as cinco capabilities como uma lista mental de verificação durante as Demos. Quando um fornecedor diz "nossa AI analisa seus dados," pergunte: isso é Analyze (estado atual) ou Predict (probabilidade futura)? Quando eles dizem "automatiza seu Workflow," pergunte: ele Gera rascunhos ou Executa ações? Quando dizem "roteamento inteligente," pergunte se Execute está presente e qual é o mecanismo de aprovação humana.
Em um mês fazendo isso, você vai ler pitches de forma diferente. O problema dos três fornecedores de Priya se torna uma comparação de 15 minutos em vez de um julgamento intuitivo de 60 minutos. E o tagging de iniciativas se torna o primeiro passo em qualquer brief de projeto, não uma reflexão tardia.
Cinco verbos. Seis tipos de dados. Dez padrões. A prática é o que faz isso se fixar.
Este artigo faz parte da coleção ACE Framework Foundation. Leitura relacionada: a fronteira entre Generate e Execute, tagging de iniciativas de AI, e os aprofundamentos em Predict e Execute.

Senior Operations & Growth Strategist
On this page
- O protocolo de tagging ACE: 5 perguntas em ordem
- Cinco exemplos práticos
- Exemplo 1: Lead scoring do Salesforce Einstein
- Exemplo 2: Análise de ligações do Gong
- Exemplo 3: ChatGPT escrevendo um e-mail de vendas
- Exemplo 4: Automação de notas fiscais do Bill.com com AI
- Exemplo 5: Cursor e Claude Code (agentes de codificação autônomos)
- Sua vez: a planilha de auditoria
- Erros comuns ao fazer o tagging
- Usando tags ACE para decisões de compra
- Construindo o reflexo