Cómo Leer un Caso de Uso de AI con la Fórmula ACE
Priya dirige una empresa de software B2B de 75 personas. El negocio va bien. El producto avanza rápido, el equipo de ventas está alcanzando sus objetivos y el directorio está haciendo las preguntas correctas.
Pero el mes pasado algo cambió. Tres propuestas de proveedores distintas llegaron en la misma semana. Una herramienta de inteligencia de ventas. Una plataforma de automatización de facturas. Un asistente de escritura con AI para el equipo de marketing. Cada proveedor afirmaba que su solución era "impulsada por AI." Cada uno mostró una demo impecable. Cada uno prometía "transformar" un flujo de trabajo.
Al terminar la tercera demo, Priya se dio cuenta de que los estaba evaluando a todos por intuición en lugar de por estructura. Le gustó la interfaz del primero. El vendedor del segundo era convincente. El tercero tenía un caso de estudio de una empresa que conocía. Nada de eso era un marco de compra.
Le pidió a su Director de Operaciones que comparara los tres. Dos días después, él regresó. "No sé cómo compararlos," dijo. "Ni siquiera están haciendo lo mismo."
Tenía razón. Pero no tenía el vocabulario para demostrarlo.
Este artículo le proporciona ese vocabulario. Una vez que entiende el ACE Framework y sus cinco capacidades fundamentales, puede etiquetar cualquier producto de AI en menos de cinco minutos. El problema de Priya tiene solución: un protocolo de cinco pasos, cinco ejemplos prácticos y una hoja de trabajo que su equipo puede usar antes de cualquier evaluación de proveedor.
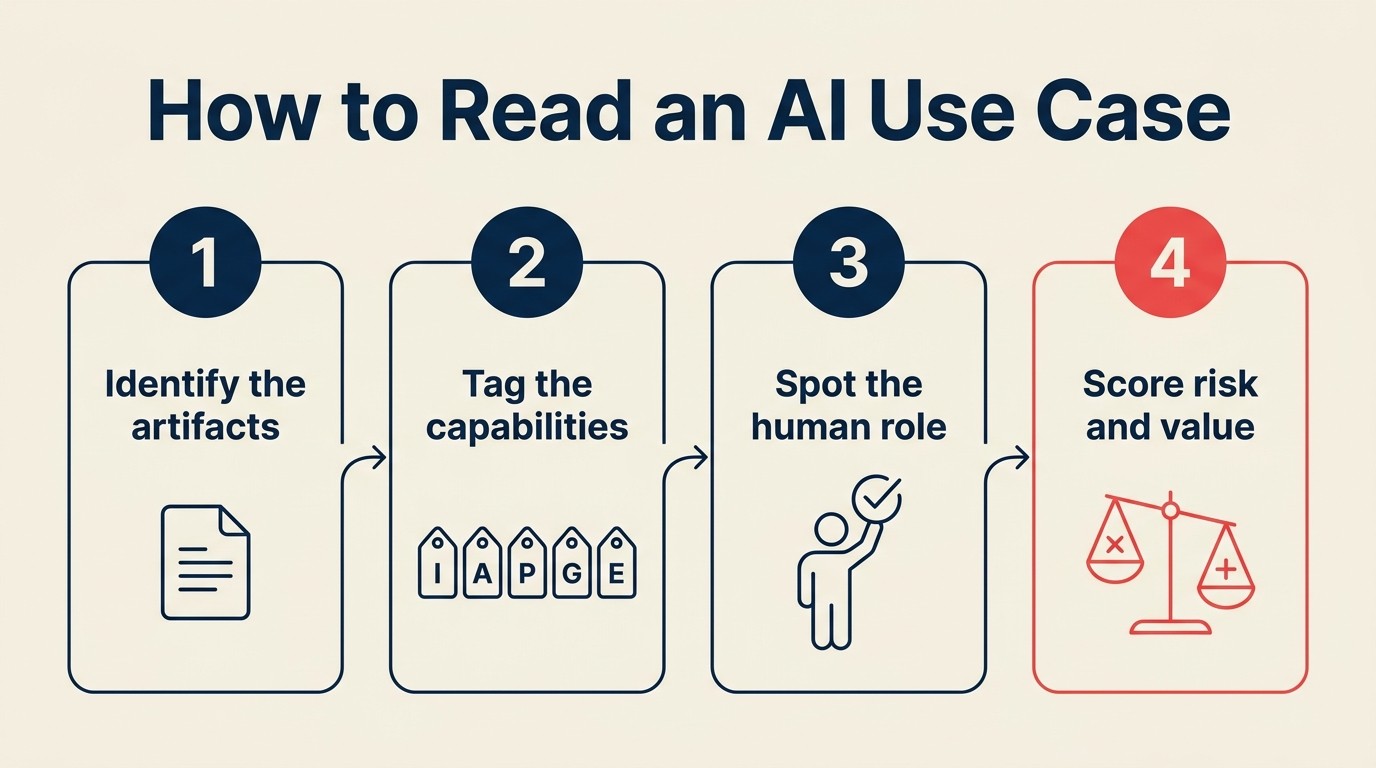
El protocolo de etiquetado ACE: 5 preguntas en orden
El ACE Framework describe la AI empresarial como cinco capacidades que operan sobre datos: Ingest, Analyze, Predict, Generate, Execute. El protocolo de etiquetado aplica esos cinco conceptos en secuencia a cualquier caso de uso. Usted está construyendo un recibo, no emitiendo un juicio.
Haga estas preguntas en orden:
Paso 1: ¿Qué datos consume?
Empiece por la base. Cada capacidad necesita datos, y el tipo de datos condiciona todo lo que viene después. ¿Texto? ¿Registros estructurados? ¿Imágenes? ¿Audio? ¿Código? Muchas herramientas consumen múltiples tipos, pero generalmente hay uno primario. Si no puede identificar la entrada, no puede etiquetar nada más.
Paso 2: ¿Qué capacidades utiliza?
Recorra cada uno de los cinco verbos. ¿Hace Ingest (convierte señales sin procesar en forma utilizable)? ¿Analyze (clasifica, extrae, resume)? ¿Predict (puntúa probabilidades, pronostica resultados)? ¿Generate (produce texto, imágenes, código, planes)? ¿Execute (cambia el estado en un sistema externo)? La mayoría de los productos reales usan de dos a cuatro capacidades en secuencia. Enumere todas las que apliquen.
Paso 3: ¿Cuál es el patrón dominante?
Las combinaciones de capacidades se agrupan en patrones reutilizables. Analyze + Predict sobre registros entrantes es Scoring y Routing. Ingest sobre audio que alimenta Analyze y Generate es Meeting Intelligence. Ingest sobre imágenes que alimentan Analyze en una actualización de registro es Vision Extract. El patrón le dice qué herramientas adyacentes hacen el mismo trabajo y qué modos de fallo esperar.
Paso 4: ¿El resultado es un artefacto o un cambio de estado?
Este es el límite entre Generate y Execute. Generate produce un borrador: un email, una puntuación, un resumen que espera a que ocurra algo a continuación. Execute cambia el estado externo: envía el email, actualiza el registro de CRM, emite el reembolso. Ese límite importa para la gobernanza. Una herramienta que Execute de forma autónoma sin su aprobación tiene un perfil de riesgo diferente al de una que solo genera borradores.
Paso 5: ¿Dónde encaja el humano en el bucle?
¿Hay una compuerta de revisión antes de que se ejecute algo? ¿Monitorización a posteriori? ¿O el bucle es completamente autónomo? Execute completamente autónomo es la configuración de mayor riesgo. Es apropiada en algunos casos, pero debe ser una decisión de diseño explícita, no un descuido.
Cinco ejemplos prácticos
Ejemplo 1: Lead scoring de Salesforce Einstein
Lo que dice que hace: "Lead scoring impulsado por AI que le indica a sus representantes qué leads priorizar."
Etiquetado ACE:
| Pregunta | Respuesta |
|---|---|
| Datos consumidos | Estructurados (registros de CRM: firmografía, historial de etapas de negocio, interacciones con leads, tasas de apertura de email) |
| Capacidades | Analyze (extraer características relevantes de los registros de CRM) + Predict (generar una puntuación de probabilidad por lead) |
| Patrón dominante | Scoring y Routing |
| Resultado | Una puntuación (Generate) que opcionalmente desencadena asignación automática (Execute) |
| Humano en el bucle | Los representantes revisan sus leads de alta puntuación. Los managers pueden configurar reglas de asignación automática |
Lo que esto le dice: Einstein es principalmente una herramienta de Predict con un paso de preprocesamiento de Analyze. No escribe emails, analiza audio de llamadas ni actualiza campos de CRM por sí solo. Si su equipo lo está evaluando para automatizar el outreach, eso no es lo que hace. La capacidad Execute (asignación automática) existe pero es opcional. La mayoría de los equipos empiezan con la puntuación como señal para los representantes humanos, no como disparador de acción automatizada.
Error común: Esperar que Predict funcione sin datos históricos limpios. Si su CRM no tiene resultados etiquetados (registros ganados/perdidos vinculados a características firmográficas), el modelo de scoring no tiene nada de lo que aprender. Los datos históricos limpios son el prerrequisito. Datos basura, puntuaciones basura.
Ejemplo 2: Análisis de llamadas de Gong
Lo que dice que hace: "Inteligencia de ingresos a partir de sus llamadas de ventas. La AI revela qué está funcionando y por qué se cierran los negocios."
Etiquetado ACE:
| Pregunta | Respuesta |
|---|---|
| Datos consumidos | Audio (llamadas grabadas) + Texto (transcripciones) + Estructurados (registros de CRM para contexto de negocio) |
| Capacidades | Ingest (audio a transcripción mediante speech-to-text) + Analyze (temas, objeciones, sentimiento, ratio de tiempo de habla) + Generate (resumen de llamada, insights de coaching, sugerencias de próximos pasos) + Execute (escribir notas de CRM, enviar a Salesforce) |
| Patrón dominante | Meeting Intelligence |
| Resultado | Ambos. Los resúmenes e insights de coaching son Generate (artefactos para revisión humana). Las actualizaciones de notas de CRM son Execute (cambio de estado) |
| Humano en el bucle | Los representantes leen el resumen. Los managers revisan los dashboards de coaching. Gong no toma acciones sobre el cliente |
Lo que esto le dice: Gong usa cuatro de las cinco capacidades ACE. El paso Ingest (calidad de la transcripción) es fundamental: si las llamadas se graban en entornos ruidosos o la precisión de la transcripción es baja, cada capacidad posterior se degrada. El paso Execute (escritura en CRM) es real pero de bajo riesgo: está actualizando un campo de notas, no enviando un email ni emitiendo un reembolso.
Error común: Tratar los insights de Gong como conclusiones en lugar de señales. Analyze detecta que los representantes que preguntan sobre el timing cierran a mayor tasa. Eso es una correlación de datos pasados. Es un estímulo para investigar, no un playbook probado.
Ejemplo 3: ChatGPT escribiendo un email de ventas
Lo que dice que hace: Nada formalmente. Es un asistente de AI de propósito general. En este escenario, un representante lo usa para redactar un outreach.
Etiquetado ACE:
| Pregunta | Respuesta |
|---|---|
| Datos consumidos | Texto (el prompt del representante, el contexto del negocio que pega, cualquier instrucción) |
| Capacidades | Analyze (entender el prompt y el contexto) + Generate (producir el borrador del email) |
| Patrón dominante | Workflow Copilot (modo herramienta) |
| Resultado | Un borrador (solo Generate). Nada ha sido enviado |
| Humano en el bucle | Completamente en control. El representante decide si usar el borrador, editarlo o descartarlo. Execute es separado y manual |
Lo que esto le dice: ChatGPT usado de esta forma es una herramienta pura de Generate. No tiene acceso a su CRM, no puede enviar nada y no sabe nada sobre el prospecto real más allá de lo que el representante pega. El perfil de riesgo es bajo: en el peor caso, es un borrador deficiente que se descarta. Pero también es la razón por la que el techo de productividad es limitado. Cada resultado requiere que un humano lo verifique y lo envíe.
Esta es la fórmula ACE más sencilla en la práctica. Analyze + Generate, sin Execute, el humano decide todo. Una vez que lo etiqueta así, la comparación con un agente SDR autónomo (que añade Execute y elimina la compuerta humana) se vuelve mucho más clara.
Ejemplo 4: Automatización de facturas con AI de Bill.com
Lo que dice que hace: "Automatice la captura y codificación de facturas. La AI extrae datos de sus facturas y las enruta para aprobación."
Etiquetado ACE:
| Pregunta | Respuesta |
|---|---|
| Datos consumidos | Imagen (escaneos de facturas, PDFs) + Estructurados (registros de proveedores, plan de cuentas) |
| Capacidades | Ingest (OCR y análisis de documentos en imagen de factura) + Analyze (extraer nombre del proveedor, partidas, montos, códigos de libro mayor) + Execute (crear registro de factura, establecer calendario de pago, enrutar para aprobación) |
| Patrón dominante | Vision Extract |
| Resultado | Los datos estructurados extraídos (resultado de Analyze) se convierten en un registro de factura en vivo (Execute) |
| Humano en el bucle | Existen compuertas de aprobación. Las facturas por encima de un umbral de dólares configurable requieren la firma humana antes del pago |
Lo que esto le dice: El paso Ingest es donde se originan la mayoría de los problemas de precisión: formularios rellenados a mano, diseños inusuales y escaneos de baja resolución degradan el OCR. El paso Execute tiene consecuencias reales: los calendarios de pago y las colas de aprobación son registros en vivo en su sistema. La compuerta de aprobación humana es el diseño correcto, pero necesita configurarse explícitamente. La mayoría de los equipos subestiman cuánto importa el umbral de dólares.
Error común: Establecer el umbral de aprobación demasiado alto (digamos, 5.000 dólares) y asumir que todo lo que está por debajo es de bajo riesgo. Una oleada de facturas duplicadas pequeñas del mismo proveedor a 800 dólares cada una puede pasar desapercibida. La capacidad Analyze no verifica duplicados a menos que esa lógica esté explícitamente construida.
Ejemplo 5: Cursor y Claude Code (agentes de código autónomos)
Lo que dice que hace: "Un agente de código AI que lee su codebase, escribe código según la especificación, ejecuta pruebas y abre un pull request."
Etiquetado ACE:
| Pregunta | Respuesta |
|---|---|
| Datos consumidos | Código (el repositorio, archivos existentes, PRs anteriores) + Texto (la especificación o descripción del issue, instrucciones del usuario) |
| Capacidades | Las cinco. Ingest (leer y analizar el codebase) + Analyze (entender la estructura existente, encontrar los archivos relevantes) + Predict (determinar el enfoque de implementación más probable y correcto) + Generate (escribir los cambios de código) + Execute (ejecutar pruebas, crear el PR, opcionalmente hacer merge) |
| Patrón dominante | Agente Autónomo |
| Resultado | Los cambios de código son Generate. La creación del PR y la ejecución de pruebas son Execute. El merge (si está configurado) es Execute de alta consecuencia |
| Humano en el bucle | Revisa el PR antes del merge. Esta es la compuerta crítica. Sin ella, Execute llega a producción |
Lo que esto le dice: Las cinco capacidades ACE están activas, lo que significa que los cinco modos de fallo están activos simultáneamente. Ingest puede malinterpretar un codebase desconocido. Analyze puede identificar erróneamente los archivos relevantes. Predict puede elegir una implementación técnicamente correcta pero arquitectónicamente equivocada. Generate puede escribir código que pasa las pruebas pero introduce errores de lógica sutiles. Execute (el merge) es irreversible en producción.
La compuerta de revisión del PR antes del merge es el único punto donde un humano puede detectar fallos de cualquiera de las cuatro capacidades anteriores. Los equipos que la eliminan para "automatizar completamente" los pipelines de despliegue están eliminando la válvula de seguridad de los cinco modos de fallo a la vez.
Vale la pena destacar: Cursor y Claude Code difieren en alcance. Cursor es principalmente un Workflow Copilot (con Generate dominante, el humano conduce cada paso en el IDE). Claude Code puede operar de forma más autónoma (capaz de Execute, tareas de múltiples pasos). Etiquetar ambos fuerza la distinción que "herramienta de código AI" oculta por completo.
Su turno: la hoja de auditoría
Ejecute esto para tres herramientas de AI que su equipo usa ahora mismo. No empiece con la documentación del proveedor. Empiece con lo que la herramienta realmente hace en su flujo de trabajo, luego mapee hacia atrás.
Para cada herramienta, complete esta tabla:
| Campo | Su respuesta |
|---|---|
| Nombre de la herramienta | |
| ¿Qué consume? (tipos de datos) | |
| ¿Qué capacidades ACE utiliza? | |
| ¿Qué patrón coincide? | |
| ¿El resultado es un borrador (Generate) o un cambio de estado (Execute)? | |
| ¿Dónde está el humano en el bucle? | |
| ¿Qué ocurre si la AI se equivoca en cada capacidad? |
Luego responda estas tres preguntas:
- ¿Qué capacidad domina? (La que impulsa la mayor parte de la propuesta de valor de la herramienta.)
- ¿Ejecuta? Si es así, ¿los guardrails de Execute están explícitos y documentados, o se asumen?
- Comparando dos herramientas que usa en la misma categoría: ¿están usando la misma fórmula ACE o fórmulas diferentes?
La tercera pregunta es la reveladora. Dos herramientas de "inteligencia de CRM" pueden parecer idénticas en una demo pero usar combinaciones de capacidades completamente diferentes. Una es Analyze + Generate (resume notas de negocio, redacta próximos pasos). La otra es Analyze + Predict + Execute (puntúa el estado del negocio, pronostica el cierre, enruta automáticamente los negocios en riesgo a un manager). El etiquetado ACE hace visible esa diferencia en 10 minutos en lugar de una demo de 60.
Errores comunes al etiquetar
Error 1: Confundir Analyze con Predict.
Analyze responde "¿qué es esto?" Predict responde "¿qué es probable que ocurra a continuación?" Una herramienta que clasifica tickets de soporte por tipo es Analyze. Una herramienta que puntúa qué tickets tienen probabilidad de escalar a churn es Predict (con Analyze como entrada). También fallan de forma diferente. El fallo de Analyze aparece de inmediato (clasificación incorrecta). El fallo de Predict aparece semanas después cuando las estimaciones de probabilidad se alejan de la realidad.
Error 2: Pasar por alto Execute.
Los equipos subestiman Execute porque ocurre en segundo plano. Una herramienta de Meeting Intelligence que "actualiza su CRM después de las llamadas" está ejecutando. Una herramienta de lead scoring que "asigna automáticamente al representante correcto" está ejecutando. Si solo ve el Dashboard, se perderá las llamadas a la API que ya están cambiando registros en su sistema. Revise la configuración de integración, no solo la interfaz. Permisos de escritura, webhooks, triggers de automatización: eso es Execute.
Error 3: Subestimar los tipos de datos.
Gong no solo procesa audio. Ingiere el registro de CRM, el audio de la llamada y la transcripción simultáneamente. El audio lleva la señal, pero el contexto de CRM (etapa del negocio, tamaño de la empresa, representante) es lo que hace útiles a Analyze y Predict. Etiquete solo el canal principal y se perderá las dependencias de datos, y los modos de fallo que aparecen cuando las entradas secundarias son desordenadas.
Error 4: Listar capacidades sin nombrar el patrón.
Una lista de capacidades es una lista de componentes. Un patrón es el ensamblaje. Dos herramientas pueden usar Analyze + Generate, pero una es un Workflow Copilot (conducido por el humano, resultado único, iterativo) y la otra es un motor de revisión de documentos (procesamiento por lotes, múltiples documentos, resultado estructurado). El patrón le dice qué modos de fallo son más probables y qué cambios en el flujo de trabajo requiere la herramienta. Las capacidades sin un patrón son la mitad de una etiqueta.
Usar las etiquetas ACE para decisiones de compra
Encuentre redundancias en su stack. Etiquete todas sus herramientas de AI actuales y ponga los resultados uno al lado del otro. Tres herramientas haciendo Analyze + Generate sobre texto es una oportunidad de consolidación. Cero herramientas haciendo Predict a pesar de pagar por "analítica predictiva" es una brecha. Las etiquetas le muestran la forma de su inversión real en AI, que suele ser diferente de lo que cree que tiene.
Compare herramientas honestamente. Dos "herramientas de ventas con AI" pueden usar fórmulas ACE completamente diferentes. Si una es Analyze + Generate y la otra es Analyze + Predict + Execute, están resolviendo problemas distintos. Está comparando un copiloto con un motor de automatización. Esa distinción debe guiar sus criterios de evaluación, no la calidad de la demo.
Haga coincidir la fórmula con la necesidad real. La mayoría de los errores de compra ocurren porque los equipos saben que quieren "AI para X" pero no han identificado qué capacidad necesitan para X. ¿Productividad de los representantes (redactar más rápido)? Necesita Generate. ¿Priorización (en qué negocios concentrarse)? Necesita Predict. ¿Entrada de datos manual desde documentos? Necesita Ingest + Analyze + Execute. Empezar por la necesidad de capacidad, no por la etiqueta de categoría, le lleva a la lista corta correcta más rápido.
Un apunte: el protocolo de etiquetado es un diagnóstico, no una puntuación. Una herramienta con cinco capacidades no es mejor que una con dos. Un Agente Autónomo mal gobernado que usa las cinco es más arriesgado que un copiloto sencillo de solo Generate. Lo que importa es si la combinación de capacidades resuelve su problema real, si los pasos de Execute están adecuadamente protegidos y si los datos que alimentan el sistema son lo suficientemente limpios para confiar en ellos.
Desarrollar el reflejo
El objetivo no es etiquetar cada herramienta perfectamente a la primera. El objetivo es desarrollar el reflejo.
Empiece con las cinco capacidades como lista de verificación mental durante las demos. Cuando un proveedor dice "nuestra AI analiza sus datos," pregunte: ¿es Analyze (estado actual) o Predict (probabilidad futura)? Cuando dicen "automatiza su flujo de trabajo," pregunte: ¿genera borradores o ejecuta acciones? Cuando dicen "enrutamiento inteligente," pregunte si Execute está presente y cuál es el mecanismo de aprobación humana.
En un mes de esto, leerá las propuestas de forma diferente. El problema de Priya con tres proveedores se convierte en una comparación de 15 minutos en lugar de una revisión de 60 minutos basada en intuición. Y etiquetar iniciativas se convierte en el primer paso de cualquier resumen de proyecto, no en una ocurrencia tardía.
Cinco verbos. Seis tipos de datos. Diez patrones. La práctica es lo que hace que todo encaje.
Este artículo es parte de la colección ACE Framework Foundation. Lectura relacionada: el límite entre Generate y Execute, etiquetado de iniciativas de AI, y los análisis en profundidad sobre Predict y Execute.

Senior Operations & Growth Strategist
On this page
- El protocolo de etiquetado ACE: 5 preguntas en orden
- Cinco ejemplos prácticos
- Ejemplo 1: Lead scoring de Salesforce Einstein
- Ejemplo 2: Análisis de llamadas de Gong
- Ejemplo 3: ChatGPT escribiendo un email de ventas
- Ejemplo 4: Automatización de facturas con AI de Bill.com
- Ejemplo 5: Cursor y Claude Code (agentes de código autónomos)
- Su turno: la hoja de auditoría
- Errores comunes al etiquetar
- Usar las etiquetas ACE para decisiones de compra
- Desarrollar el reflejo