Cara Membaca Kes Penggunaan AI Menggunakan Formula ACE
Kenali Priya. Dia mengetuai syarikat perisian B2B dengan 75 orang pekerja. Perniagaan berjalan baik. Produk dihantar dengan pantas, pasukan jualan mencapai kuota, dan lembaga pengarah mengajukan soalan yang tepat.
Tetapi bulan lalu, sesuatu berubah. Tiga pembentangan vendor yang berbeza tiba dalam minggu yang sama. Alat perisikan jualan. Platform automasi invois. Pembantu penulisan AI untuk pasukan pemasaran. Setiap vendor mendakwa "dikuasakan AI." Setiap satu menunjukkan demo yang cantik. Setiap satu berjanji untuk "mengubah" aliran kerja.
Menjelang akhir demo ketiga, Priya menyedari bahawa dia menilai semuanya berdasarkan perasaan dan bukannya berdasarkan struktur. Dia menyukai antaramuka yang pertama. Jurujual yang kedua memukau. Yang ketiga mempunyai kajian kes dari syarikat yang pernah dia dengar. Tiada satu pun daripada itu adalah rangka kerja pembelian.
Dia meminta Ketua Operasinya membandingkan ketiga-tiga. Dia kembali dua hari kemudian. "Saya tidak tahu cara membandingkannya," katanya. "Mereka tidak melakukan perkara yang sama."
Dia betul. Tetapi dia tidak mempunyai perbendaharaan kata untuk membuktikannya.
Artikel ini memberi anda perbendaharaan kata itu. Sebaik sahaja anda memahami ACE Framework dan lima keupayaan terasnya, anda boleh menandakan mana-mana produk AI dalam masa kurang lima minit. Masalah Priya mempunyai penyelesaian: protokol lima langkah, lima contoh yang dikerjakan, dan lembaran kerja yang boleh dijalankan pasukannya sebelum mana-mana penilaian vendor.
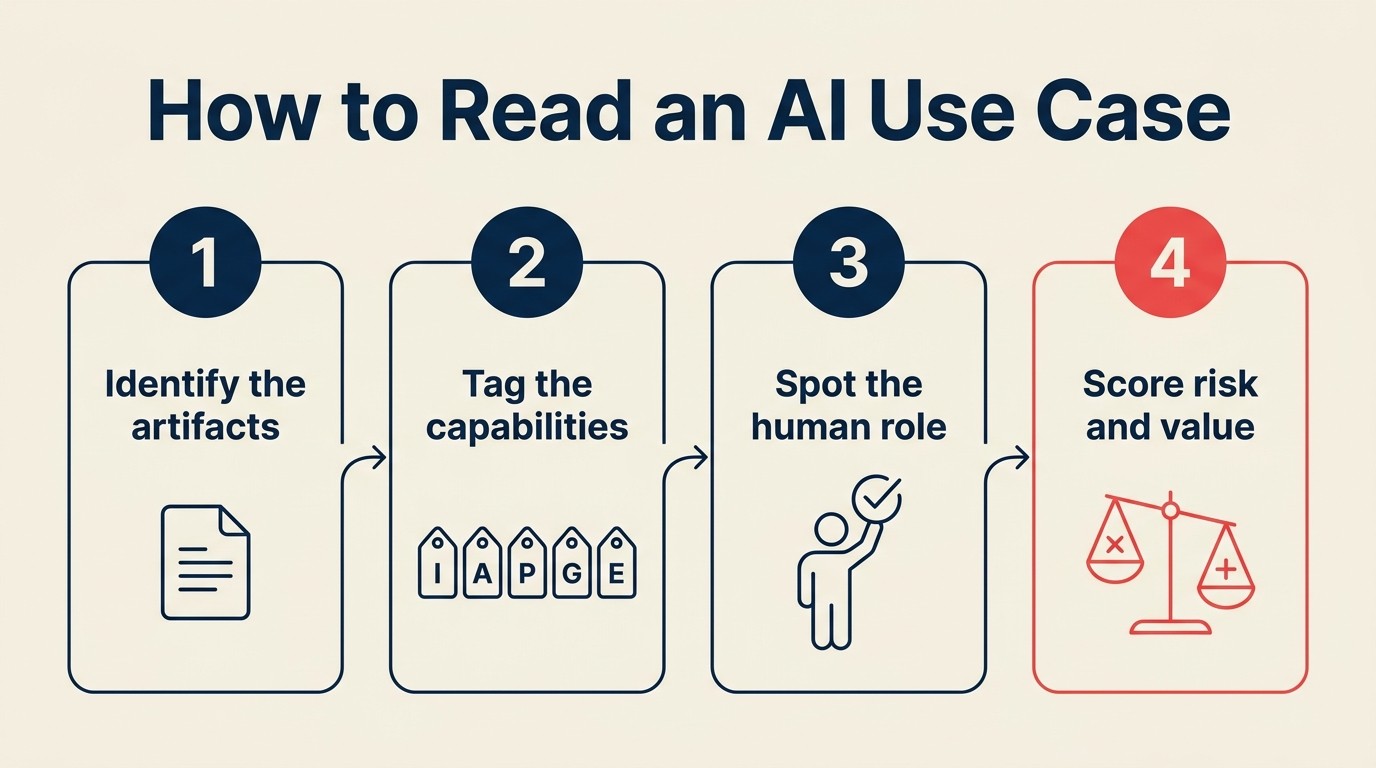
Protokol penandaan ACE: 5 soalan mengikut urutan
ACE Framework menggambarkan AI perniagaan sebagai lima keupayaan yang beroperasi pada data: Ingest, Analyze, Predict, Generate, Execute. Protokol penandaan menerapkan lima konsep tersebut secara berurutan kepada mana-mana kes penggunaan. Anda sedang membina resit, bukan membuat penilaian subjektif.
Tanya soalan-soalan ini mengikut urutan:
Langkah 1: Data apa yang ia gunakan?
Mulakan di asas. Setiap keupayaan memerlukan data, dan jenis data membentuk segala-galanya yang berikutnya. Teks? Rekod berstruktur? Imej? Audio? Kod? Banyak alat menggunakan pelbagai jenis, tetapi biasanya ada satu yang utama. Jika anda tidak boleh mengenal pasti input, anda tidak boleh menandakan apa-apa yang lain.
Langkah 2: Keupayaan mana yang digunakannya?
Lalui setiap lima kata kerja. Adakah ia Ingest (menukar isyarat mentah kepada bentuk yang boleh digunakan)? Analyze (mengklasifikasikan, mengekstrak, merumuskan)? Predict (menilai kebarangkalian, meramal hasil)? Generate (menghasilkan teks, imej, kod, pelan)? Execute (menukar keadaan dalam sistem luaran)? Kebanyakan produk sebenar menggunakan dua hingga empat keupayaan secara berurutan. Senaraikan semua yang berkenaan.
Langkah 3: Apakah corak yang dominan?
Gabungan keupayaan membentuk kelompok corak yang boleh digunakan semula. Analyze + Predict pada rekod masuk adalah Pemarkahan dan Penghalaan. Ingest pada audio yang memberi makan Analyze dan Generate adalah Perisikan Mesyuarat. Ingest pada imej yang memberi makan Analyze ke dalam kemaskini rekod adalah Pengekstrakan Visual. Corak memberitahu anda alat bersebelahan mana yang melakukan kerja yang sama dan mod kegagalan apa yang perlu dijangka.
Langkah 4: Apakah output: artifak atau perubahan keadaan?
Ini adalah sempadan Generate vs. Execute. Generate menghasilkan draf: e-mel, skor, ringkasan yang menunggu sesuatu berlaku seterusnya. Execute mengubah keadaan luaran: menghantar e-mel, mengemas kini rekod CRM, mengeluarkan bayaran balik. Sempadan itu penting untuk tadbir urus. Alat yang melaksanakan Execute secara autonomi tanpa kelulusan anda mempunyai profil risiko yang berbeza berbanding yang hanya menghasilkan draf.
Langkah 5: Di mana manusia berada dalam gelung?
Adakah terdapat pintu semakan sebelum apa-apa Execute? Pemantauan selepas itu? Atau adakah gelung itu sepenuhnya autonomi? Execute yang sepenuhnya autonomi adalah konfigurasi berisiko tertinggi. Ia sesuai kadang kala, tetapi ia seharusnya menjadi keputusan reka bentuk yang eksplisit, bukan sesuatu yang terlepas pandang.
Lima contoh yang dikerjakan
Contoh 1: Pemarkahan lead Salesforce Einstein
Apa yang didakwanya: "Pemarkahan lead berkuasa AI yang memberitahu wakil anda lead mana yang perlu diutamakan."
Penandaan ACE:
| Soalan | Jawapan |
|---|---|
| Data yang digunakan | Berstruktur (rekod CRM: firmografi, sejarah peringkat urusan niaga, interaksi lead, kadar buka e-mel) |
| Keupayaan | Analyze (mengekstrak ciri relevan daripada rekod CRM) + Predict (output skor kebarangkalian bagi setiap lead) |
| Corak dominan | Pemarkahan dan Penghalaan |
| Output | Skor (Generate) yang secara pilihan mencetuskan penugasan automatik (Execute) |
| Manusia dalam gelung | Wakil menyemak lead berskor tinggi mereka. Pengurus boleh mengkonfigurasi peraturan penghalaan automatik |
Apa yang ini memberitahu anda: Einstein pada dasarnya adalah alat Predict dengan langkah praproses Analyze. Ia tidak menulis e-mel, menganalisis audio panggilan, atau mengemas kini medan CRM sendiri. Jika pasukan anda membeli-belahnya untuk mengautomasikan jangkauan, itu bukan yang dilakukannya. Keupayaan Execute (penghalaan automatik) wujud tetapi pilihan. Kebanyakan pasukan bermula dengan skor sebagai isyarat untuk wakil manusia, bukan sebagai pencetus tindakan automatik.
Kesilapan biasa: Mengharapkan Predict berfungsi tanpa data sejarah yang bersih. Jika CRM anda tidak mempunyai hasil berlabel (rekod menang/kalah yang dikaitkan dengan ciri firmografi), model pemarkahan tidak mempunyai apa-apa untuk dipelajari. Data sejarah yang bersih adalah prasyarat. Input sampah, skor sampah.
Contoh 2: Analisis panggilan Gong
Apa yang didakwanya: "Perisikan hasil daripada panggilan jualan anda. AI mendedahkan apa yang berjaya dan mengapa urusan niaga ditutup."
Penandaan ACE:
| Soalan | Jawapan |
|---|---|
| Data yang digunakan | Audio (panggilan yang dirakam) + Teks (transkrip) + Berstruktur (rekod CRM untuk konteks urusan niaga) |
| Keupayaan | Ingest (audio ke transkrip melalui pertuturan-ke-teks) + Analyze (topik, bantahan, sentimen, nisbah masa bercakap) + Generate (ringkasan panggilan, pandangan bimbingan, cadangan langkah seterusnya) + Execute (tulis nota CRM, tolak ke Salesforce) |
| Corak dominan | Perisikan Mesyuarat |
| Output | Kedua-duanya. Ringkasan dan pandangan bimbingan adalah Generate (artifak untuk semakan manusia). Kemaskini nota CRM adalah Execute (perubahan keadaan) |
| Manusia dalam gelung | Wakil membaca ringkasan. Pengurus menyemak papan pemuka bimbingan. Gong tidak mengambil tindakan ke atas pelanggan |
Apa yang ini memberitahu anda: Gong menggunakan empat daripada lima keupayaan ACE. Langkah Ingest (kualiti transkripsi) adalah asas: jika panggilan dirakam dalam persekitaran bising atau ketepatan transkripsi rendah, setiap keupayaan hiliran merosot. Langkah Execute (tulis balik ke CRM) adalah nyata tetapi berisiko rendah: ia mengemas kini medan nota, bukan menghantar e-mel atau mengeluarkan bayaran balik.
Kesilapan biasa: Menganggap pandangan Gong sebagai kesimpulan dan bukannya isyarat. Analyze menandakan bahawa wakil yang bertanya tentang jadual waktu tutup pada kadar yang lebih tinggi. Itu adalah korelasi daripada data lampau. Ia adalah dorongan untuk menyiasat, bukan panduan yang terbukti.
Contoh 3: ChatGPT menulis e-mel jualan
Apa yang didakwanya: Tiada secara formal. Ia adalah pembantu AI tujuan umum. Dalam senario ini, seorang wakil menggunakannya untuk merangka jangkauan.
Penandaan ACE:
| Soalan | Jawapan |
|---|---|
| Data yang digunakan | Teks (arahan wakil, konteks urusan niaga yang mereka tampal, sebarang arahan) |
| Keupayaan | Analyze (memahami arahan dan konteks) + Generate (menghasilkan draf e-mel) |
| Corak dominan | Copilot Aliran Kerja (mod alat) |
| Output | Draf (Generate sahaja). Tiada yang telah dihantar |
| Manusia dalam gelung | Sepenuhnya dalam kawalan. Wakil memutuskan sama ada untuk menggunakan draf, menyuntingnya, atau membuangnya. Execute adalah berasingan dan manual |
Apa yang ini memberitahu anda: ChatGPT yang digunakan dengan cara ini adalah alat Generate tulen. Ia tidak mempunyai akses kepada CRM anda, tidak boleh menghantar apa-apa, dan tidak tahu apa-apa tentang bakal pelanggan sebenar selain apa yang ditampal oleh wakil. Profil risiko adalah rendah: dalam kes terburuk ia adalah draf yang buruk yang dibuang. Tetapi itulah juga sebabnya siling produktiviti adalah terhad. Setiap output memerlukan manusia untuk mengesahkan dan mengeluarkan.
Ini adalah formula ACE paling mudah dalam amalan. Analyze + Generate, tiada Execute, manusia memutuskan segalanya. Sebaik sahaja anda menandakannya dengan cara ini, perbandingan dengan agen SDR autonomi (yang menambah Execute dan membuang pintu manusia) menjadi jauh lebih tajam.
Contoh 4: Automasi invois AI Bill.com
Apa yang didakwanya: "Automatikkan tangkapan dan pengekodan invois. AI mengekstrak data daripada invois anda dan menghalanya untuk kelulusan."
Penandaan ACE:
| Soalan | Jawapan |
|---|---|
| Data yang digunakan | Imej (imbasan invois, PDF) + Berstruktur (rekod induk vendor, carta akaun) |
| Keupayaan | Ingest (OCR dan penghuraian dokumen pada imej invois) + Analyze (ekstrak nama vendor, item baris, jumlah, kod GL) + Execute (cipta rekod invois, tetapkan jadual pembayaran, halakan untuk kelulusan) |
| Corak dominan | Pengekstrakan Visual |
| Output | Data berstruktur yang diekstrak (output Analyze) menjadi rekod invois langsung (Execute) |
| Manusia dalam gelung | Pintu kelulusan wujud. Invois melebihi had dolar yang boleh dikonfigurasi memerlukan pengesahan manusia sebelum pembayaran |
Apa yang ini memberitahu anda: Langkah Ingest adalah tempat kebanyakan masalah ketepatan bermula: borang yang diisi dengan tangan, tata letak yang tidak biasa, dan imbasan resolusi rendah semuanya merosotkan OCR. Langkah Execute mempunyai akibat sebenar: jadual pembayaran dan baris gilir kelulusan adalah rekod langsung dalam sistem anda. Pintu kelulusan manusia adalah reka bentuk yang betul, tetapi ia perlu dikonfigurasi secara eksplisit. Kebanyakan pasukan meremehkan betapa pentingnya had dolar.
Kesilapan biasa: Menetapkan had kelulusan terlalu tinggi (katakan, $5,000) dan menganggap segala-galanya di bawah adalah berisiko rendah. Gelombang invois pendua kecil daripada vendor yang sama pada $800 setiap satu boleh terlepas. Keupayaan Analyze tidak menyemak pendua melainkan logik itu dibina secara eksplisit.
Contoh 5: Cursor dan Claude Code (agen pengekodan autonomi)
Apa yang didakwanya: "Agen pengekodan AI yang membaca kod asas anda, menulis kod mengikut spesifikasi, menjalankan ujian, dan membuka permintaan tarik."
Penandaan ACE:
| Soalan | Jawapan |
|---|---|
| Data yang digunakan | Kod (repositori, fail sedia ada, PR lepas) + Teks (spesifikasi atau huraian isu, arahan pengguna) |
| Keupayaan | Kesemua lima. Ingest (baca dan hurai kod asas) + Analyze (fahami struktur sedia ada, cari fail yang relevan) + Predict (tentukan pendekatan pelaksanaan yang paling mungkin betul) + Generate (tulis perubahan kod) + Execute (jalankan ujian, cipta PR, secara pilihan gabungkan) |
| Corak dominan | Agen Autonomi |
| Output | Perubahan kod adalah Generate. Penciptaan PR dan pelaksanaan ujian adalah Execute. Penggabungan (jika dikonfigurasi) adalah Execute dengan akibat tinggi |
| Manusia dalam gelung | Menyemak PR sebelum penggabungan. Ini adalah pintu kritikal. Tanpanya, Execute mencapai pengeluaran |
Apa yang ini memberitahu anda: Kesemua lima keupayaan ACE aktif, bermakna kesemua lima mod kegagalan aktif secara serentak. Ingest boleh salah membaca kod asas yang tidak dikenali. Analyze boleh salah mengenal pasti fail yang relevan. Predict boleh memilih pelaksanaan yang betul secara teknikal tetapi salah secara seni bina. Generate boleh menulis kod yang lulus ujian tetapi memperkenalkan ralat logik yang halus. Execute (penggabungan) adalah tidak boleh dibalikkan dalam pengeluaran.
Pintu PR-sebelum-gabung adalah satu-satunya titik di mana manusia boleh menangkap kegagalan daripada mana-mana empat keupayaan sebelumnya. Pasukan yang membuangnya untuk "mengautomasikan sepenuhnya" saluran paip penempatan sedang membuang injap keselamatan pada kesemua lima mod kegagalan sekaligus.
Perlu diingat: Cursor dan Claude Code berbeza dalam skop. Cursor pada dasarnya adalah Copilot Aliran Kerja (berat Generate, manusia memandu setiap langkah dalam IDE). Claude Code boleh beroperasi lebih autonomi (mampu Execute, tugasan berbilang langkah). Menandakan kedua-duanya memaksa perbezaan yang "alat pengekodan AI" sembunyikan sepenuhnya.
Giliran anda: lembaran kerja audit
Jalankan ini untuk tiga alat AI yang digunakan pasukan anda sekarang. Jangan mulakan dengan dokumentasi vendor. Mulakan dengan apa yang alat itu sebenarnya lakukan dalam aliran kerja anda, kemudian petakan ke belakang.
Untuk setiap alat, lengkapkan jadual ini:
| Medan | Jawapan anda |
|---|---|
| Nama alat | |
| Apa yang digunakannya? (jenis data) | |
| Keupayaan ACE mana yang digunakannya? | |
| Corak apa yang dipadankannya? | |
| Adakah output itu draf (Generate) atau perubahan keadaan (Execute)? | |
| Di mana manusia berada dalam gelung? | |
| Apa yang berlaku jika AI tersilap pada setiap keupayaan? |
Kemudian jawab tiga soalan ini:
- Keupayaan mana yang dominan? (Yang memacu sebahagian besar cadangan nilai alat.)
- Adakah ia Execute? Jika ya, adakah kawalan perlindungan Execute eksplisit dan didokumentasikan, atau sekadar diandaikan?
- Membandingkan dua alat yang anda gunakan dalam kategori yang sama: adakah mereka menggunakan formula ACE yang sama, atau yang berbeza?
Soalan ketiga adalah yang paling mendedahkan. Dua alat perisikan CRM boleh kelihatan identik dalam demo tetapi menggunakan gabungan keupayaan yang sangat berbeza. Satu adalah Analyze + Generate (merumuskan nota urusan niaga, merangka langkah seterusnya). Satu lagi adalah Analyze + Predict + Execute (menilai kesihatan urusan niaga, meramal penutupan, menghalakan secara automatik urusan niaga berisiko kepada pengurus). Penandaan ACE mendedahkan perbezaan itu dalam 10 minit berbanding demo 60 minit.
Kesilapan biasa semasa menandakan
Kesilapan 1: Mengelirukan Analyze dengan Predict.
Analyze menjawab "apakah ini?" Predict menjawab "apakah yang mungkin seterusnya?" Alat yang mengklasifikasikan tiket sokongan mengikut jenis adalah Analyze. Alat yang menilai tiket mana yang mungkin meningkat kepada churn adalah Predict (dengan Analyze sebagai input). Mereka juga gagal secara berbeza. Kegagalan Analyze muncul dengan segera (klasifikasi yang salah). Kegagalan Predict muncul berminggu-minggu kemudian apabila anggaran kebarangkalian menyimpang daripada realiti.
Kesilapan 2: Terlepas pandang Execute.
Pasukan mengecilkan kiraan Execute kerana ia berlaku di belakang tabir. Alat perisikan mesyuarat yang "mengemas kini CRM anda selepas panggilan" sedang Execute. Alat pemarkahan lead yang "menugaskan secara automatik kepada wakil yang tepat" sedang Execute. Jika anda hanya melihat papan pemuka, anda terlepas panggilan API yang sudah mengubah rekod dalam sistem anda. Telusuri tetapan integrasi, bukan hanya antaramuka. Kebenaran tulis, webhook, pencetus automasi — itu semua adalah Execute.
Kesilapan 3: Mengecilkan kiraan jenis data.
Gong bukan sekadar memproses audio. Ia sedang mengingesti rekod CRM, audio panggilan, dan transkrip secara serentak. Audio membawa isyarat, tetapi konteks CRM (peringkat urusan niaga, saiz syarikat, wakil) adalah yang menjadikan Analyze dan Predict berguna. Tandakan hanya saluran utama dan anda akan terlepas kebergantungan data — dan mod kegagalan yang muncul apabila input sekunder tidak teratur.
Kesilapan 4: Menyenaraikan keupayaan tanpa menamakan corak.
Senarai keupayaan adalah senarai bahagian. Corak adalah pemasangan. Dua alat mungkin sama-sama menggunakan Analyze + Generate, tetapi satu adalah Copilot Aliran Kerja (didorong manusia, output tunggal, berulang) dan yang lain adalah enjin Semakan Dokumen (diproses secara kelompok, berbilang dokumen, output berstruktur). Corak memberitahu anda mod kegagalan mana yang paling mungkin dan perubahan aliran kerja apa yang diperlukan oleh alat. Keupayaan tanpa corak adalah setengah tanda.
Menggunakan tanda ACE untuk keputusan pembelian
Cari lebihan dalam susun atur anda. Tandakan semua alat AI semasa anda dan letakkan hasilnya bersebelahan. Tiga alat yang melakukan Analyze + Generate pada teks adalah peluang penyatuan. Sifar alat yang melakukan Predict walaupun membayar untuk "analitik ramalan" adalah jurang. Tanda-tanda menunjukkan bentuk pelaburan AI sebenar anda, yang sering berbeza daripada apa yang anda fikir anda miliki.
Bandingkan alat secara jujur. Dua "alat jualan AI" boleh menggunakan formula ACE yang sangat berbeza. Jika satu adalah Analyze + Generate dan yang lain adalah Analyze + Predict + Execute, mereka menyelesaikan masalah yang berbeza. Anda sedang membandingkan copilot dengan enjin automasi. Perbezaan itu seharusnya memacu kriteria penilaian anda, bukan kualiti demo.
Padankan formula dengan keperluan sebenar. Kebanyakan kesilapan pembelian berlaku kerana pasukan tahu mereka mahukan "AI untuk X" tetapi belum mengenal pasti keupayaan mana yang mereka perlukan untuk X. Produktiviti wakil (merangka lebih pantas)? Anda memerlukan Generate. Keutamaan (urusan niaga mana yang perlu difokuskan)? Anda memerlukan Predict. Kemasukan data manual daripada dokumen? Anda memerlukan Ingest + Analyze + Execute. Bermula dengan keperluan keupayaan, bukan label kategori, membawa anda kepada senarai pendek yang tepat dengan lebih pantas.
Satu nota: protokol penandaan adalah diagnostik, bukan skor. Alat dengan lima keupayaan tidak lebih baik daripada alat dengan dua. Agen Autonomi yang tidak diurus dengan baik yang menggunakan kesemua lima adalah lebih berisiko daripada copilot Generate-sahaja yang mudah. Yang penting adalah sama ada campuran keupayaan menyelesaikan masalah sebenar anda, sama ada langkah Execute dilindungi dengan sewajarnya, dan sama ada data yang memberi makan sistem itu cukup bersih untuk dipercayai.
Membina refleks
Matlamatnya bukan untuk menandakan setiap alat dengan sempurna pada percubaan pertama. Matlamatnya adalah untuk membina refleks.
Mulakan dengan lima keupayaan sebagai senarai semak mental semasa demo. Apabila vendor berkata "AI kami menganalisis data anda," tanya: adakah itu Analyze (keadaan semasa) atau Predict (kebarangkalian masa depan)? Apabila mereka berkata "mengautomasikan aliran kerja anda," tanya: adakah ia menghasilkan draf Generate atau melaksanakan tindakan Execute? Apabila mereka berkata "penghalaan pintar," tanya sama ada Execute wujud dan apakah mekanisme kelulusan manusia.
Dalam sebulan amalan ini, anda akan membaca pembentangan dengan cara yang berbeza. Masalah tiga vendor Priya menjadi perbandingan 15 minit berbanding semakan instinct 60 minit. Dan menandakan inisiatif menjadi langkah pertama dalam mana-mana ringkasan projek, bukan fikiran kemudian.
Lima kata kerja. Enam jenis data. Sepuluh corak. Amalanlah yang menjadikannya sebati.
Artikel ini adalah sebahagian daripada koleksi ACE Framework Foundation. Bacaan berkaitan: sempadan Generate vs. Execute, menandakan inisiatif AI, dan pemahaman mendalam tentang Predict dan Execute.

Senior Operations & Growth Strategist
On this page
- Protokol penandaan ACE: 5 soalan mengikut urutan
- Lima contoh yang dikerjakan
- Contoh 1: Pemarkahan lead Salesforce Einstein
- Contoh 2: Analisis panggilan Gong
- Contoh 3: ChatGPT menulis e-mel jualan
- Contoh 4: Automasi invois AI Bill.com
- Contoh 5: Cursor dan Claude Code (agen pengekodan autonomi)
- Giliran anda: lembaran kerja audit
- Kesilapan biasa semasa menandakan
- Menggunakan tanda ACE untuk keputusan pembelian
- Membina refleks