Cara Membaca Use Case AI Menggunakan Formula ACE
Perkenalkan Priya. Ia mengelola perusahaan software B2B dengan 75 karyawan. Bisnis berjalan baik. Produk berkembang pesat, tim penjualan mencapai kuota, dan board mengajukan pertanyaan yang tepat.
Tetapi bulan lalu, ada yang berubah. Tiga pitch vendor terpisah datang dalam satu minggu. Sebuah tool intelijen penjualan. Platform otomatisasi faktur. Asisten penulisan AI untuk tim marketing. Setiap vendor mengklaim "berbasis AI." Setiap vendor menampilkan demo yang sempurna. Setiap vendor berjanji untuk "mengubah" suatu workflow.
Di akhir demo ketiga, Priya menyadari ia menilai ketiganya berdasarkan perasaan, bukan struktur. Ia menyukai antarmuka yang pertama. Sales rep yang kedua meyakinkan. Yang ketiga memiliki case study dari perusahaan yang pernah ia dengar. Tidak satu pun dari itu adalah kerangka pembelian.
Ia meminta Head of Operations-nya untuk membandingkan ketiganya. Ia kembali dua hari kemudian. "Saya tidak tahu bagaimana membandingkannya," katanya. "Mereka bahkan tidak melakukan hal yang sama."
Ia benar. Tapi ia tidak punya kosakata untuk membuktikannya.
Artikel ini memberi Anda kosakata itu. Setelah memahami ACE Framework dan lima kapabilitas intinya, Anda bisa menandai produk AI apa pun dalam waktu kurang dari lima menit. Masalah Priya memiliki solusi: protokol lima langkah, lima contoh yang dikerjakan, dan lembar kerja yang bisa dijalankan timnya sebelum evaluasi vendor apa pun.
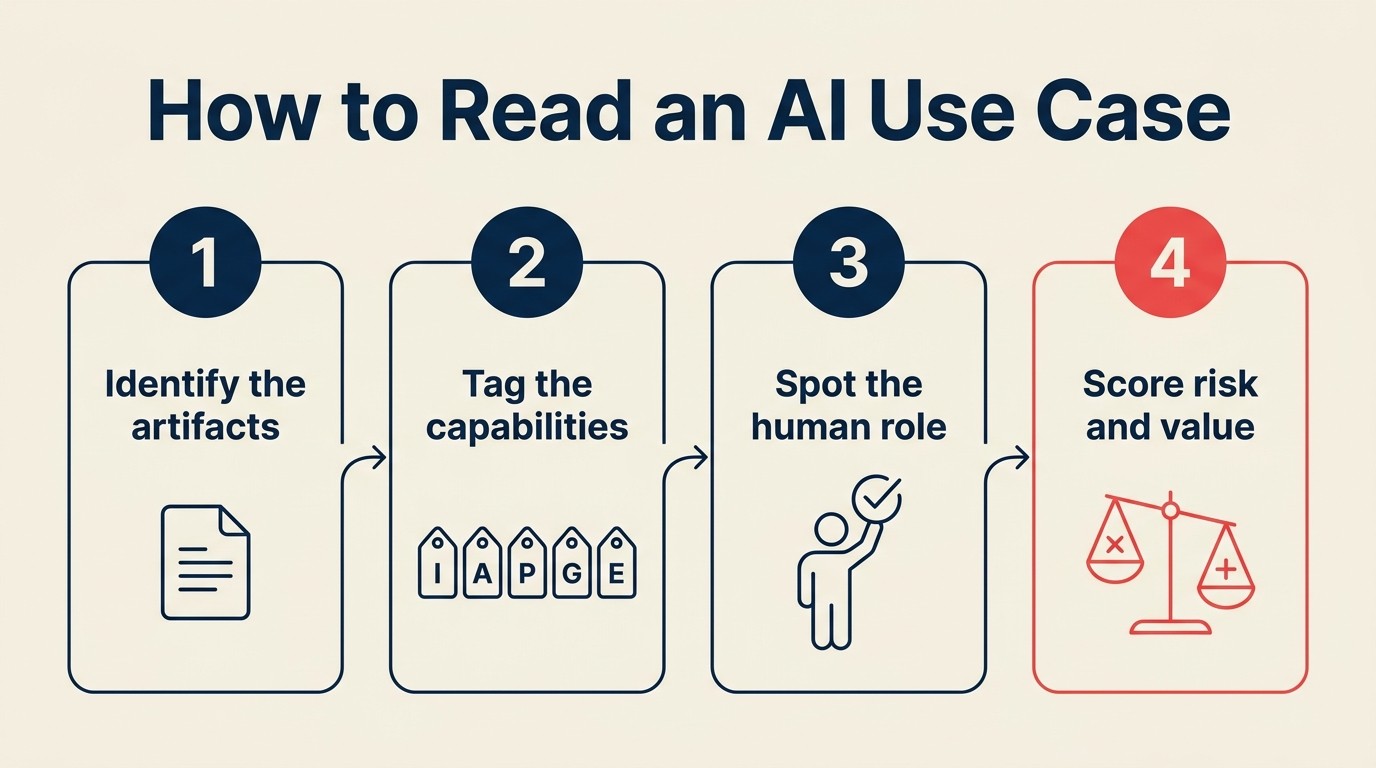
Protokol tagging ACE: 5 pertanyaan berurutan
ACE Framework menggambarkan AI bisnis sebagai lima kapabilitas yang beroperasi pada data: Ingest, Analyze, Predict, Generate, Execute. Protokol tagging menerapkan lima konsep tersebut secara berurutan pada use case apa pun. Anda sedang membangun receipt, bukan penilaian subjektif.
Ajukan pertanyaan-pertanyaan ini berurutan:
Langkah 1: Data apa yang dikonsumsinya?
Mulai dari fondasi. Setiap kapabilitas membutuhkan data, dan tipe data membentuk segalanya di hilir. Teks? Rekaman terstruktur? Gambar? Audio? Kode? Banyak tools mengonsumsi beberapa tipe, tetapi biasanya ada yang dominan. Jika Anda tidak bisa mengidentifikasi inputnya, Anda tidak bisa menandai apa pun.
Langkah 2: Kapabilitas mana yang digunakannya?
Lalui setiap dari lima kata kerja. Apakah ia Ingest (mengubah sinyal mentah menjadi bentuk yang dapat digunakan)? Analyze (mengklasifikasi, mengekstrak, merangkum)? Predict (memberi skor probabilitas, memperkirakan hasil)? Generate (menghasilkan teks, gambar, kode, rencana)? Execute (mengubah status di sistem eksternal)? Sebagian besar produk nyata menggunakan dua hingga empat kapabilitas secara berurutan. Daftarkan semua yang berlaku.
Langkah 3: Apa pola dominannya?
Kombinasi kapabilitas mengelompok menjadi pola yang dapat digunakan kembali. Analyze + Predict pada rekaman masuk adalah Scoring and Routing. Ingest pada audio yang memberi Analyze dan Generate adalah Meeting Intelligence. Ingest pada gambar yang memberi Analyze ke pembaruan rekaman adalah Vision Extract. Pola tersebut memberi tahu Anda tools apa yang melakukan pekerjaan yang sama dan mode kegagalan apa yang harus diantisipasi.
Langkah 4: Apa outputnya: artefak atau perubahan status?
Ini adalah batas Generate vs. Execute. Generate menghasilkan draf: email, skor, ringkasan yang menunggu sesuatu terjadi selanjutnya. Execute mengubah status eksternal: mengirim email, memperbarui rekaman CRM, menerbitkan refund. Batas itu penting untuk tata kelola. Tool yang Execute secara otonom tanpa persetujuan Anda memiliki profil risiko yang berbeda dari yang hanya Generate draf.
Langkah 5: Di mana manusia berada dalam loop?
Apakah ada review gate sebelum apa pun yang Execute? Pemantauan setelah fakta? Atau apakah loop sepenuhnya otonom? Execute otonom penuh adalah konfigurasi paling berisiko. Ini terkadang tepat, tetapi harus menjadi keputusan desain yang eksplisit, bukan kelalaian.
Lima contoh yang dikerjakan
Contoh 1: Lead scoring Salesforce Einstein
Yang diklaim untuk dilakukan: "Lead scoring berbasis AI yang memberi tahu rep Anda lead mana yang harus diprioritaskan."
Tagging ACE:
| Pertanyaan | Jawaban |
|---|---|
| Data yang dikonsumsi | Terstruktur (rekaman CRM: firmografi, riwayat tahap deal, interaksi lead, tingkat buka email) |
| Kapabilitas | Analyze (ekstrak fitur relevan dari rekaman CRM) + Predict (output skor probabilitas per lead) |
| Pola dominan | Scoring and Routing |
| Output | Skor (Generate) yang secara opsional memicu penetapan otomatis (Execute) |
| Manusia dalam loop | Rep meninjau lead skor tinggi mereka. Manajer bisa mengonfigurasi aturan auto-routing |
Yang ini memberi tahu Anda: Einstein terutama adalah tool Predict dengan langkah preprocessing Analyze. Ia tidak menulis email, menganalisis audio panggilan, atau memperbarui field CRM sendiri. Jika tim Anda membelinya untuk mengotomatisasi outreach, bukan itu yang dilakukannya. Kapabilitas Execute (auto-routing) ada tetapi opsional. Sebagian besar tim memulai dengan skor sebagai sinyal untuk rep manusia, bukan sebagai pemicu tindakan otomatis.
Kesalahan umum: Mengharapkan Predict bekerja tanpa data historis yang bersih. Jika CRM Anda tidak memiliki hasil berlabel (rekaman menang/kalah yang terhubung dengan fitur firmografi), model scoring tidak punya apa-apa untuk dipelajari. Data historis yang bersih adalah prasyaratnya. Sampah masuk, skor sampah keluar.
Contoh 2: Analisis panggilan Gong
Yang diklaim untuk dilakukan: "Revenue intelligence dari panggilan penjualan Anda. AI menampilkan apa yang berhasil dan mengapa deal ditutup."
Tagging ACE:
| Pertanyaan | Jawaban |
|---|---|
| Data yang dikonsumsi | Audio (panggilan yang direkam) + Teks (transkrip) + Terstruktur (rekaman CRM untuk konteks deal) |
| Kapabilitas | Ingest (audio ke transkrip melalui speech-to-text) + Analyze (topik, keberatan, sentimen, rasio waktu bicara) + Generate (ringkasan panggilan, insight pelatihan, saran langkah berikutnya) + Execute (tulis catatan CRM, dorong ke Salesforce) |
| Pola dominan | Meeting Intelligence |
| Output | Keduanya. Ringkasan dan insight pelatihan adalah Generate (artefak untuk ditinjau manusia). Pembaruan catatan CRM adalah Execute (perubahan status) |
| Manusia dalam loop | Rep membaca ringkasan. Manajer meninjau Dashboard pelatihan. Gong tidak mengambil tindakan pada pelanggan |
Yang ini memberi tahu Anda: Gong menggunakan empat dari lima kapabilitas ACE. Langkah Ingest (kualitas transkripsi) adalah fondasi: jika panggilan direkam di lingkungan berisik atau akurasi transkripsi rendah, setiap kapabilitas hilir menurun kualitasnya. Langkah Execute (write-back CRM) nyata tetapi rendah risiko: memperbarui field catatan, bukan mengirim email atau menerbitkan refund.
Kesalahan umum: Memperlakukan insight Gong sebagai kesimpulan daripada sinyal. Analyze menandai bahwa rep yang bertanya tentang timeline menutup dengan tingkat yang lebih tinggi. Itu adalah korelasi dari data masa lalu. Ini adalah dorongan untuk diselidiki, bukan playbook yang terbukti.
Contoh 3: ChatGPT menulis email penjualan
Yang diklaim untuk dilakukan: Tidak ada secara formal. Ini adalah asisten AI tujuan umum. Dalam skenario ini, seorang rep menggunakannya untuk menyusun outreach.
Tagging ACE:
| Pertanyaan | Jawaban |
|---|---|
| Data yang dikonsumsi | Teks (prompt rep, konteks deal yang mereka tempel, instruksi apa pun) |
| Kapabilitas | Analyze (pahami prompt dan konteks) + Generate (hasilkan draf email) |
| Pola dominan | Workflow Copilot (mode tool) |
| Output | Sebuah draf (Generate saja). Tidak ada yang dikirim |
| Manusia dalam loop | Sepenuhnya dalam kendali. Rep memutuskan apakah akan menggunakan draf, mengeditnya, atau membuangnya. Execute terpisah dan manual |
Yang ini memberi tahu Anda: ChatGPT yang digunakan dengan cara ini adalah tool Generate murni. Ia tidak memiliki akses ke CRM Anda, tidak bisa mengirim apa pun, dan tidak tahu apa-apa tentang prospek sebenarnya selain apa yang ditempel rep. Profil risikonya rendah: kasus terburuk adalah draf buruk yang dibuang. Tetapi inilah juga mengapa plafon produktivitasnya terbatas. Setiap output memerlukan manusia untuk memverifikasi dan mendorongnya keluar.
Ini adalah formula ACE paling sederhana dalam praktik. Analyze + Generate, tidak ada Execute, manusia memutuskan segalanya. Setelah Anda menandainya dengan cara ini, perbandingan dengan agen SDR otonom (yang menambahkan Execute dan menghapus gate manusia) menjadi jauh lebih tajam.
Contoh 4: Otomatisasi faktur AI Bill.com
Yang diklaim untuk dilakukan: "Otomatisasi penangkapan dan pengkodean faktur. AI mengekstrak data dari faktur Anda dan mengarahkannya untuk persetujuan."
Tagging ACE:
| Pertanyaan | Jawaban |
|---|---|
| Data yang dikonsumsi | Gambar (scan faktur, PDF) + Terstruktur (rekaman master vendor, bagan akun) |
| Kapabilitas | Ingest (OCR dan parsing dokumen pada gambar faktur) + Analyze (ekstrak nama vendor, item baris, jumlah, kode GL) + Execute (buat rekaman faktur, tetapkan jadwal pembayaran, arahkan untuk persetujuan) |
| Pola dominan | Vision Extract |
| Output | Data terstruktur yang diekstrak (output Analyze) menjadi rekaman faktur langsung (Execute) |
| Manusia dalam loop | Gate persetujuan ada. Faktur di atas ambang batas dolar yang dapat dikonfigurasi memerlukan tanda tangan manusia sebelum pembayaran |
Yang ini memberi tahu Anda: Langkah Ingest adalah tempat sebagian besar masalah akurasi berasal: formulir yang diisi tangan, tata letak tidak biasa, dan scan beresolusi rendah semua menurunkan kualitas OCR. Langkah Execute memiliki konsekuensi nyata: jadwal pembayaran dan antrean persetujuan adalah rekaman langsung dalam sistem Anda. Gate persetujuan manusia adalah desain yang tepat, tetapi perlu dikonfigurasi secara eksplisit. Sebagian besar tim meremehkan seberapa pentingnya ambang batas dolar.
Kesalahan umum: Menetapkan ambang persetujuan terlalu tinggi (misalnya $5.000) dan mengasumsikan semua yang di bawahnya berisiko rendah. Serangkaian faktur duplikat kecil dari vendor yang sama masing-masing seharga $800 bisa lolos. Kapabilitas Analyze tidak memeriksa duplikat kecuali logika tersebut secara eksplisit dibangun.
Contoh 5: Cursor dan Claude Code (agen pengkodean otonom)
Yang diklaim untuk dilakukan: "Agen pengkodean AI yang membaca codebase Anda, menulis kode sesuai spesifikasi, menjalankan tes, dan membuka pull request."
Tagging ACE:
| Pertanyaan | Jawaban |
|---|---|
| Data yang dikonsumsi | Kode (repositori, file yang ada, PR masa lalu) + Teks (spesifikasi atau deskripsi issue, instruksi pengguna) |
| Kapabilitas | Semua lima. Ingest (baca dan parse codebase) + Analyze (pahami struktur yang ada, temukan file relevan) + Predict (tentukan pendekatan implementasi yang paling mungkin benar) + Generate (tulis perubahan kode) + Execute (jalankan tes, buat PR, opsional merge) |
| Pola dominan | Autonomous Agent |
| Output | Perubahan kode adalah Generate. Pembuatan PR dan eksekusi tes adalah Execute. Merge (jika dikonfigurasi) adalah Execute dengan konsekuensi tinggi |
| Manusia dalam loop | Meninjau PR sebelum merge. Inilah gate kritisnya. Tanpanya, Execute menjangkau produksi |
Yang ini memberi tahu Anda: Semua lima kapabilitas ACE aktif, yang berarti semua lima mode kegagalan berjalan secara bersamaan. Ingest bisa salah membaca codebase yang tidak familiar. Analyze bisa salah mengidentifikasi file relevan. Predict bisa memilih implementasi yang secara teknis benar tetapi secara arsitektural salah. Generate bisa menulis kode yang lulus tes tetapi menimbulkan error logika yang halus. Execute (merge) tidak bisa dibalik di produksi.
Gate PR-sebelum-merge adalah satu-satunya titik di mana manusia bisa menangkap kegagalan dari keempat kapabilitas sebelumnya. Tim yang menghapusnya untuk "mengotomatisasi sepenuhnya" pipeline deployment sedang menghapus katup pengaman untuk semua lima mode kegagalan sekaligus.
Perlu dicatat: Cursor dan Claude Code berbeda dalam cakupan. Cursor terutama adalah Workflow Copilot (berat Generate, manusia mengendalikan setiap langkah di IDE). Claude Code bisa beroperasi lebih otonom (berkemampuan Execute, tugas multi-langkah). Menandai keduanya memaksa perbedaan yang sepenuhnya disembunyikan oleh "tool pengkodean AI."
Giliran Anda: lembar kerja audit
Jalankan ini untuk tiga tools AI yang digunakan tim Anda sekarang. Jangan mulai dengan dokumentasi vendor. Mulai dengan apa yang sebenarnya dilakukan tool dalam workflow Anda, lalu petakan ke belakang.
Untuk setiap tool, lengkapi tabel ini:
| Field | Jawaban Anda |
|---|---|
| Nama tool | |
| Apa yang dikonsumsinya? (tipe data) | |
| Kapabilitas ACE mana yang digunakannya? | |
| Pola apa yang cocok? | |
| Apakah outputnya draf (Generate) atau perubahan status (Execute)? | |
| Di mana manusia dalam loop? | |
| Apa yang terjadi jika AI salah pada setiap kapabilitas? |
Kemudian jawab tiga pertanyaan ini:
- Kapabilitas mana yang dominan? (Yang mendorong sebagian besar value proposition tool.)
- Apakah ia Execute? Jika ya, apakah guardrail Execute eksplisit dan terdokumentasi, atau diasumsikan?
- Membandingkan dua tools yang Anda gunakan dalam kategori yang sama: apakah mereka menggunakan formula ACE yang sama, atau berbeda?
Pertanyaan ketiga yang paling mengungkapkan. Dua tools intelijen CRM bisa terlihat identik dalam demo tetapi menggunakan kombinasi kapabilitas yang sangat berbeda. Satu adalah Analyze + Generate (merangkum catatan deal, menyusun langkah berikutnya). Lainnya adalah Analyze + Predict + Execute (memberi skor kesehatan deal, memperkirakan penutupan, auto-routing deal berisiko ke manajer). Tagging ACE memunculkan perbedaan itu dalam 10 menit daripada demo 60 menit.
Kesalahan umum saat melakukan tagging
Kesalahan 1: Mencampuradukkan Analyze dengan Predict.
Analyze menjawab "apa ini?" Predict menjawab "apa yang kemungkinan terjadi selanjutnya?" Tool yang mengklasifikasikan tiket support berdasarkan tipe adalah Analyze. Tool yang memberi skor tiket mana yang kemungkinan akan berujung pada churn adalah Predict (dengan Analyze sebagai input). Keduanya juga gagal secara berbeda. Kegagalan Analyze terlihat segera (klasifikasi salah). Kegagalan Predict terlihat berminggu-minggu kemudian ketika estimasi probabilitas menyimpang dari realitas.
Kesalahan 2: Melewatkan Execute.
Tim tidak menghitung Execute karena ada di balik layar. Tool meeting intelligence yang "memperbarui CRM setelah panggilan" sedang Execute. Tool lead scoring yang "secara otomatis menetapkan ke rep yang tepat" sedang Execute. Jika Anda hanya melihat Dashboard, Anda melewatkan panggilan API yang sudah mengubah rekaman dalam sistem Anda. Lalui pengaturan integrasi, bukan hanya antarmuka. Izin tulis, webhook, pemicu otomatisasi — itu adalah Execute.
Kesalahan 3: Meremehkan tipe data.
Gong tidak hanya memproses audio. Ia sedang mengingesti rekaman CRM, audio panggilan, dan transkrip secara bersamaan. Audio membawa sinyal, tetapi konteks CRM (tahap deal, ukuran perusahaan, rep) adalah yang membuat Analyze dan Predict berguna. Tandai hanya saluran primer dan Anda akan melewatkan ketergantungan data — dan mode kegagalan yang muncul ketika input sekunder berantakan.
Kesalahan 4: Mendaftar kapabilitas tanpa menyebut pola.
Daftar kapabilitas adalah daftar suku cadang. Pola adalah rakitannya. Dua tools mungkin keduanya menggunakan Analyze + Generate, tetapi satu adalah Workflow Copilot (digerakkan manusia, output tunggal, iteratif) dan yang lain adalah mesin Document Review (diproses batch, multi-dokumen, output terstruktur). Polanya memberi tahu Anda mode kegagalan mana yang paling mungkin dan perubahan workflow apa yang diperlukan tool tersebut. Kapabilitas tanpa pola adalah setengah tag.
Menggunakan tag ACE untuk keputusan pembelian
Temukan redundansi dalam stack Anda. Tandai semua tools AI Anda saat ini dan letakkan hasilnya berdampingan. Tiga tools yang melakukan Analyze + Generate pada teks adalah peluang konsolidasi. Nol tools yang melakukan Predict meskipun membayar untuk "predictive analytics" adalah kesenjangan. Tag menunjukkan bentuk investasi AI Anda yang sebenarnya, yang sering berbeda dari apa yang Anda pikir Anda miliki.
Bandingkan tools secara jujur. Dua "tools penjualan AI" bisa menggunakan formula ACE yang sangat berbeda. Jika satu adalah Analyze + Generate dan yang lain adalah Analyze + Predict + Execute, mereka memecahkan masalah yang berbeda. Anda membandingkan copilot dengan mesin otomatisasi. Perbedaan itu harus mendorong kriteria evaluasi Anda, bukan kualitas demo.
Cocokkan formula dengan kebutuhan sebenarnya. Sebagian besar kesalahan pembelian terjadi karena tim tahu mereka menginginkan "AI untuk X" tetapi belum mengidentifikasi kapabilitas mana yang mereka butuhkan untuk X. Produktivitas rep (penyusunan lebih cepat)? Anda butuh Generate. Prioritisasi (deal mana yang harus difokuskan)? Anda butuh Predict. Entri data manual dari dokumen? Anda butuh Ingest + Analyze + Execute. Memulai dengan kebutuhan kapabilitas, bukan label kategori, membawa Anda ke shortlist yang tepat lebih cepat.
Satu catatan: protokol tagging adalah diagnostik, bukan skor. Tool dengan lima kapabilitas tidak lebih baik dari tool dengan dua kapabilitas. Autonomous Agent yang diatur dengan buruk menggunakan semua lima lebih berisiko dari copilot Generate-saja yang sederhana. Yang penting adalah apakah campuran kapabilitas memecahkan masalah Anda yang sebenarnya, apakah langkah Execute dilindungi dengan tepat, dan apakah data yang memberi sistem bersih cukup untuk dipercaya.
Membangun refleks
Tujuannya bukan untuk menandai setiap tool dengan sempurna pada percobaan pertama. Tujuannya adalah membangun refleks.
Mulai dengan lima kapabilitas sebagai checklist mental selama demo. Ketika vendor mengatakan "AI kami menganalisis data Anda," tanyakan: apakah itu Analyze (status saat ini) atau Predict (probabilitas masa depan)? Ketika mereka mengatakan "mengotomatisasi workflow Anda," tanyakan: apakah ia Generate draf atau Execute tindakan? Ketika mereka mengatakan "routing cerdas," tanyakan apakah Execute ada dan apa mekanisme persetujuan manusianya.
Dalam sebulan melakukan ini, Anda akan membaca pitch secara berbeda. Masalah tiga vendor Priya menjadi perbandingan 15 menit daripada gut check 60 menit. Dan tagging inisiatif menjadi langkah pertama dalam setiap project brief, bukan renungan.
Lima kata kerja. Enam tipe data. Sepuluh pola. Praktik itulah yang membuatnya mengakar.
Artikel ini adalah bagian dari koleksi ACE Framework Foundation. Bacaan terkait: batas Generate vs. Execute, tagging inisiatif AI, dan deep-dive tentang Predict dan Execute.

Senior Operations & Growth Strategist
On this page
- Protokol tagging ACE: 5 pertanyaan berurutan
- Lima contoh yang dikerjakan
- Contoh 1: Lead scoring Salesforce Einstein
- Contoh 2: Analisis panggilan Gong
- Contoh 3: ChatGPT menulis email penjualan
- Contoh 4: Otomatisasi faktur AI Bill.com
- Contoh 5: Cursor dan Claude Code (agen pengkodean otonom)
- Giliran Anda: lembar kerja audit
- Kesalahan umum saat melakukan tagging
- Menggunakan tag ACE untuk keputusan pembelian
- Membangun refleks